I’ve long had a problem with Truth – or at least the notion of it. It gets way too much credit for doing not much at all. For a long time now, philosophers have agreed on something uncomfortable: Truth isn’t what we once thought it was.
Truth isn’t what we once thought it was
The grand metaphysical picture, where propositions are true because they correspond to mind-independent facts, has steadily eroded. Deflationary accounts have done their work well. Truth no longer looks like a deep property hovering behind language. It looks more like a linguistic device: a way of endorsing claims, generalising across assertions, and managing disagreement. So far, so familiar.
Audio: NotebookLM summary podcast of this topic.
What’s less often asked is what happens after we take deflation seriously. Not halfway. Not politely. All the way.
That question motivates my new paper, Truth After Deflation: Why Truth Resists Stabilisation. The short version is this: once deflationary commitments are fully honoured, the concept of Truth becomes structurally unstable. Not because philosophers are confused, but because the job we keep asking Truth to do can no longer be done with the resources we allow it.
The core diagnosis: exhaustion
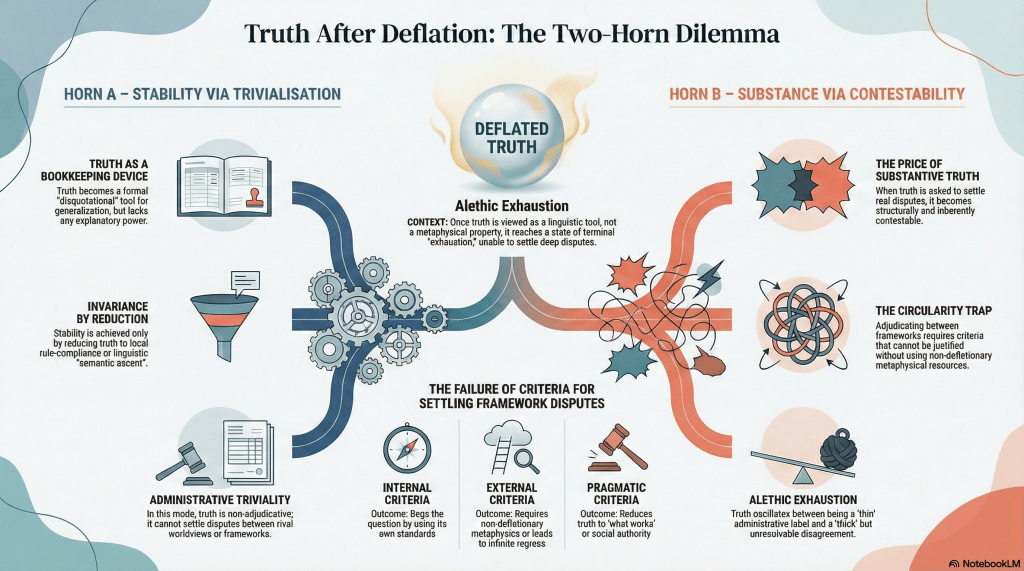
The paper introduces a deliberately unromantic idea: truth exhaustion. Exhaustion doesn’t mean that truth-talk disappears. We still say things are true. We still argue, correct one another, and care about getting things right. Exhaustion means something more specific:
After deflation, there is no metaphysical, explanatory, or adjudicative remainder left for Truth to perform.
Truth remains grammatically indispensable, but philosophically overworked.
Image: NotebookLM infographics of this topic. (Please ignore the typos.)
The dilemma
Once deflationary constraints are accepted, attempts to “save” Truth fall into a simple two-horn dilemma.
Horn A: Stabilise truth by making it invariant. You can do this by disquotation, stipulation, procedural norms, or shared observation. The result is stable, but thin. Truth becomes administrative: a device for endorsement, coordination, and semantic ascent. It no longer adjudicates between rival frameworks.
Horn B: Preserve truth as substantive. You can ask Truth to ground inquiry, settle disputes, explain success, or stand above practices. But now you need criteria. And once criteria enter, so do circularity, regress, or smuggled metaphysics. Truth becomes contestable precisely where it was meant to adjudicate.
Stability costs substance. Substance costs stability. There is no third option waiting in the wings.
Why this isn’t just abstract philosophy
To test whether this is merely a theoretical artefact, the paper works through three domains where truth is routinely asked to do serious work:
Moral truth, where Truth is meant to override local norms and condemn entrenched practices.
Scientific truth, where Truth is meant to explain success, convergence, and theory choice.
Historical truth, where Truth is meant to stabilise narratives against revisionism and denial.
In each case, the same pattern appears. When truth is stabilised, it collapses into procedure, evidence, or institutional norms. When it is thickened to adjudicate across frameworks, it becomes structurally contestable. This isn’t relativism. It’s a mismatch between function and resources.
Why this isn’t quietism either
A predictable reaction is: isn’t this just quietism in better prose?
Not quite. Quietism tells us to stop asking. Exhaustion explains why the questions keep being asked and why they keep failing. It’s diagnostic, not therapeutic. The persistence of truth-theoretic debate isn’t evidence of hidden depth. It’s evidence of a concept being pushed beyond what it can bear after deflation.
The upshot
Truth still matters. But not in the way philosophy keeps demanding. Truth works because practices work. It doesn’t ground them. It doesn’t hover above them. It doesn’t adjudicate between them without borrowing authority from elsewhere. Once that’s accepted, a great deal of philosophical anxiety dissolves, and a great deal of philosophical labour can be redirected.
The question is no longer “What is Truth?” It’s “Why did we expect Truth to do that?”
The paper is now archived on Zenodo and will propagate to PhilPapers shortly. It’s long, unapologetically structural, and aimed squarely at readers who already think deflationary truth is right but haven’t followed it to its endpoint.
Read it if you enjoy watching concepts run out of road.
My expanded direction has roots in the works of George Lakoff, Jonathan Haidt, Kurt Gray, and Joshua Greene. These people circle around the problem, even identify it, but then summarily ignore it.
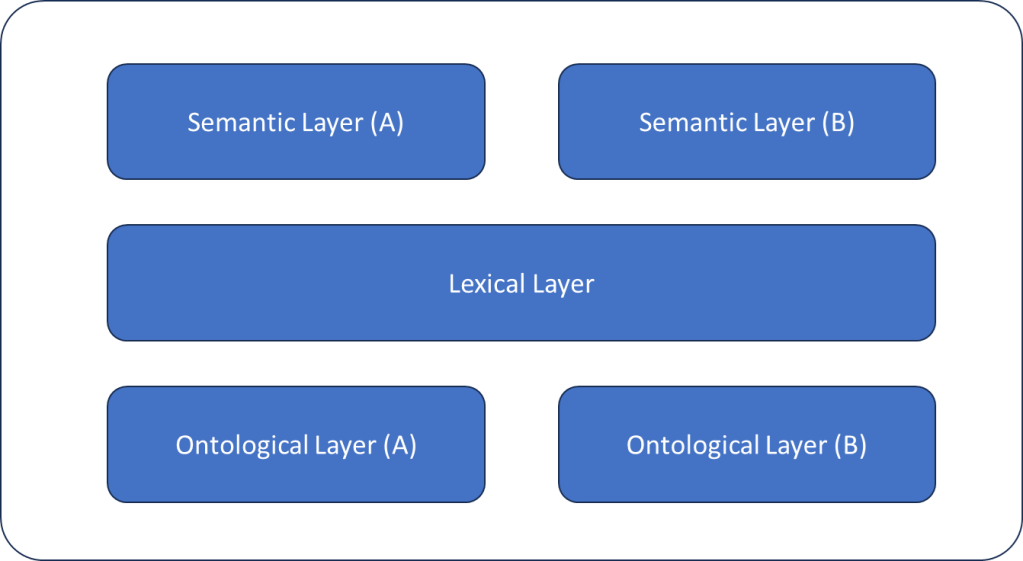
Image: This figure illustrates a simplified layered model of moral and political disagreement. Agents share a common lexical layer, enabling communication and the appearance of mutual understanding. Beneath this surface, however, ontological orientations diverge, structuring salience, legitimacy, and relevance prior to articulation. Semantic interpretation emerges downstream of these ontological commitments, producing divergent meanings despite shared vocabulary. The model highlights why disputes persist even under conditions of factual agreement and linguistic overlap: the instability lies not in words themselves, but in the ontological substrates from which semantic projections are drawn.
It’s more involved than this, but at a 50,000-foot level, it conveys the essence of my hypothesis.
I am also working on this logical expression:
∀ outcomes I(E), ∃ i,j such that Jᵢ ≠ Jⱼ
where,
Jᵢ = f(Oᵢ, E, I, RNG)
Also, in a particular context:
This will all make more sense in time. I’ll be publishing a manuscript as I study supporting research and develop my own perspectives.
A Language Insufficiency Hypothesis is now available, and I am commencing a series of video content to support it.
Video: Language Insufficiency Hypothesis – Part 1 – The Basic Concepts (Duration: 6:44)
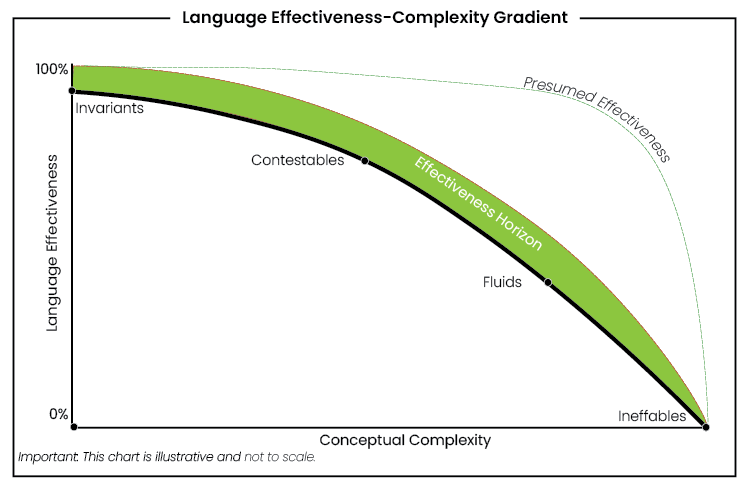
In this primer, I introduce the Language Effectiveness–Complexity Gradient and the nomenclature of the hypothesis: Invariants, Contestables, Fluids, and Ineffables.
In the next segment, I’ll discuss the Effectiveness and Presumed Effectiveness Horizons.
If you would like to support my work, consider purchasing one of my books. Leaving ratings and reviews helps more than you know to appease the algorithm gods.
Lewis Goodall, a talk show host, calls the cross-border seizure of Venezuela’s Nicolás Maduro a ‘kidnapping’. His guest and Trump apologist, Angie Wong, rejects the word. She first says ‘arrest’, then ‘extradition’, then finally the improvised ‘special extradition’. Around that single lexical choice, a 12-minute standoff unfolds.
Audio: NotebookLM summary podcast of this topic.
As a language philosopher, I am evaluating the language and am less concerned with the underlying facts of the matter. Language serves to obscure these facts from the start and then rhetorically controls the narrative and framing.
Video: Source segment being analysed
There is a familiar mistake made whenever public discourse turns heated: the assumption that the real disagreement lies in the facts. This is comforting, because facts can, at least in principle, be checked. What follows examines a different failure mode altogether. The facts are largely beside the point.
Consider a broadcast exchange in which a political commentator and an interviewer argue over how to describe the forcible removal of a head of state from one country to another. The interviewer repeatedly uses the word kidnapping. The guest repeatedly resists this term, preferring arrest, extradition, and eventually the improvisational compromise ‘special extradition’.
What matters here is not which term is correct. What matters is what the interaction reveals about how meaning is negotiated under pressure.
The illusion of disagreement
Superficially, the exchange appears to be a dispute about legality. Was there a treaty? Was due process followed? Which court has jurisdiction? These questions generate heat, but they are not doing the work.
The real disagreement is prior to all of that: which lexical frame is allowed to stabilise the event.
Once a label is accepted, downstream reasoning becomes trivial. If it was an extradition, it belongs to one legal universe. If it was a kidnapping, it belongs to another. The participants are not arguing within a shared framework; they are competing to install the framework itself.
Equivocation as method, not error
The guest’s shifting vocabulary is often described as evasive or incoherent. This misreads what is happening. The movement from extradition to special extradition is not confusion. It is a deliberate widening of semantic tolerance.
‘Special extradition’ is not meant to clarify. It is meant to survive. It carries just enough institutional residue to sound procedural, while remaining sufficiently vague to avoid binding criteria. It functions less as a description than as a holding pattern.
This is equivocation, but not the amateur kind taught in logic textbooks. It is equivocation under constraint, where the aim is not precision but narrative continuity.
Why exposure fails
The interviewer repeatedly points out that extradition has a specific meaning, and that the situation described does not meet it. This is accurate, and also ineffective.
Why? Because the exchange is no longer governed by definitional hygiene. The audience is not being asked to adjudicate a dictionary entry. They are being asked to decide which voice has the authority to name the act.
Once that shift occurs, exposing misuse does not correct the discourse. It merely clarifies the power asymmetry. The guest can concede irregularity, precedent-breaking, even illegality, without relinquishing control of the label. The language continues to function.
Truth as a downstream effect
At no point does the exchange hinge on discovering what ‘really happened’. The physical sequence of events is relatively uncontested. What is contested is what those events are allowed to count as.
In this sense, truth is not absent from the discussion; it is subordinate. It emerges only after a rhetorical frame has been successfully installed. Once the frame holds, truth follows obediently within it.
This is not relativism. It is an observation about sequence. Rhetoric does not decorate truth here; it prepares the ground on which truth is later claimed.
Language doing institutional work
The most revealing moment comes when the guest effectively shrugs at the legal ambiguity and asks who, exactly, is going to challenge it. This is not cynicism. It is diagnostic.
Words like arrest and extradition are not merely descriptive. They are operational tokens. They open doors, justify procedures, and allow institutions to proceed without stalling. Their value lies less in semantic purity than in administrative usability.
‘Kidnapping’ is linguistically precise in one register, but administratively useless in another. It stops processes rather than enabling them. That is why it is resisted.
What the case study shows
This exchange is not about geopolitics. It is about how language behaves when it is tasked with carrying power. Meaning drifts not because speakers are careless, but because precision is costly. Labels are selected for durability, not accuracy. Truth does not arbitrate rhetoric; rhetoric allocates truth. Seen this way, the debate over terminology is not a failure of communication. It is communication functioning exactly as designed under modern conditions. Which is why insisting on ‘the correct word’ increasingly feels like shouting into a ventilation system. The air still moves. It just isn’t moving for you.
Fairness, Commensurability, and the Quiet Violence of Comparison
Fairness and Commensurability as Preconditions of Retributive Justice
This is the final part of a 3-part series. Read parts 1 and 2 for a fuller context.
Audio: NotebookLM summary podcast of this topic.
Before the Cards Are Dealt
Two people invoke fairness. They mean opposite things. Both are sincere. Neither can prove the other wrong. This is not a failure of argument. It is fairness working exactly as designed.
Before justice can weigh anything, it must first decide that the things being weighed belong on the same scale. That single move – the assertion that comparison is even possible – quietly does most of the work.
Most people think justice begins at sentencing, or evidence, or procedure. But the real work happens earlier, in a space so normalised it has become invisible. Before any evaluation occurs, the system must install the infrastructure that makes evaluation legible at all.
That infrastructure rests on two foundations:
fairness, which supplies the rhetoric, and
commensurability, which supplies the mathematics.
Together, they form the felt beneath the table – the surface on which the cards can be dealt at all.
1. Why Fairness Is Always Claimed, Never Found
Let’s be precise about what fairness is not.
Fairness is not a metric. You cannot measure it, derive it, or point to it in the world.
Fairness is not a principle with determinate content. It generates no specific obligations, no falsifiable predictions, no uniquely correct outcomes.
Fairness is an effect. It appears after assessment, not before it. It is what you call an outcome when you want it to feel inevitable.
Competing Fairness Is Not a Problem
Consider how disputes actually unfold:
The prosecutor says a long sentence is fair because it is proportional to harm.
The defender says a shorter sentence is fair because it reflects culpability and circumstance.
The victim says any sentence is unfair because nothing restores what was taken.
The community says enforcement itself is unfair because it predictably targets certain groups.
Each claim is sincere. None can be resolved by fairness itself.
That is because fairness has no independent content. It does not decide between these positions. It names them once the system has already decided which will prevail. This is not a bug. It is the feature.
A Fluid Masquerading as an Invariant
In the language of the Language Insufficiency Hypothesis, fairness is a Fluid – a concept whose boundaries shift with context and use – that masquerades as an Invariant, something stable and observer-independent.
The system treats fairness as perceptual, obvious, discoverable. But every attempt to anchor it collapses into:
Intuition (‘It just feels right’)
Precedent (‘This is how we do things’)
Consensus (‘Most people agree’)
None of these establishes fairness. They merely perform it.
And that performance matters. It converts contested metaphysical commitments into the appearance of shared values. It allows institutions to claim neutrality whilst enforcing specificity. Fairness is what the system says when it wants its outputs to feel unavoidable.
2. The Real Gatekeeper: Commensurability
Fairness does rhetorical work. But it cannot function without something deeper.
That something is commensurability: the assumption that different harms, injuries, and values can be placed on a shared scale and meaningfully compared.
Proportionality presupposes commensurability. Commensurability presupposes an ontology of value. And that ontology is neither neutral nor shared.
When Incommensurability Refuses to Cooperate
A parent loses a child to preventable negligence. A corporation cuts safety corners. A warning is ignored. The system moves. Liability is established. Damages are calculated. £250,000 is awarded.
The parent refuses the settlement. Not because the amount is insufficient. But because money and loss are not the same kind of thing. The judge grows impatient. Lawyers speak of closure. Observers mutter about grief clouding judgment. But this is not grief. It is incommensurability refusing to cooperate.
The parent is rejecting the comparison itself. Accepting payment would validate the idea that a child’s life belongs on a scale with currency. The violence is not the number. It is the conversion. The system cannot process this refusal except as emotional excess or procedural obstruction. Not because it is cruel, but because without commensurability the engine cannot calculate.
Two Ontologies of Value
There are two incompatible ontologies at work here. Only one is playable.
Ontology A: The Scalar Model
Harm is quantifiable
Suffering is comparable
Trade-offs are morally coherent
Justice is a balancing operation
Under Ontology A, harms differ in degree, not kind. A broken arm, a stolen car, and a dead child all occupy points on the same continuum. This makes proportionality possible.
Ontology B: The Qualitative Model
Harms are categorical
Some losses are incommensurable
Comparison itself distorts
Justice is interpretive, not calculative
Under Ontology B, harms are different kinds of things. Comparison flattens what matters. To weigh them is to misunderstand them.
Why Only One Ontology Can Play
Retributive justice, as presently constituted, cannot function under Ontology B.
Without scalar values, proportionality collapses. Without comparison, equivalence disappears. Without trade-offs, punishment has no exchange rate.
Ontology B is not defeated. It is disqualified. Structurally, procedurally, rhetorically. The house needs a shared scale. Without it, the game cannot settle accounts.
3. Why Incommensurability Is Treated as Bad Faith
Here is where power enters without announcing itself. Incommensurability does not merely complicate disputes. It stalls the engine. And stalled engines threaten institutional legitimacy.
Systems designed to produce closure must ensure that disputes remain within solvable bounds. Incommensurability violates those bounds. It suggests that resolution may be impossible – or that the attempt to resolve does further harm. So the system reframes the problem.
Not as an alternative ontology, but as:
Unreasonableness
Extremism
Emotional volatility
Refusal to engage in good faith
Reasonableness as Border Control
This is why reasonableness belongs where it does in the model. Not as an evaluative principle, but as a gatekeeping mechanism.
Reasonableness does not assess claims. It determines which claims count as claims at all. This is how commensurability enforces itself without admitting it is doing so. When someone refuses comparison, they are not told their ontology is incompatible with retributive justice. They are told to be realistic.
Ontological disagreement is converted into:
A tone problem
A personality defect
A failure to cooperate
The disagreement is not answered. It is pathologised.
4. Why These Debates Never Resolve
This returns us to the Ontology–Encounter–Evaluation model.
People argue fairness as if adjusting weights would fix the scale. They debate severity, leniency, proportionality.
But when two sides inhabit incompatible ontologies of value, no amount of evidence or dialogue bridges the gap. The real disagreement is upstream.
A prosecutor operating under scalar harm and an advocate operating under incommensurable injury are not disagreeing about facts. They are disagreeing about what kind of thing harm is.
Fairness cannot resolve this, because fairness presupposes the very comparison under dispute. This is why reform debates feel sincere and go nowhere. Outcomes are argued whilst ontological commitments remain invisible.
Remediation Requires Switching Teams
As argued elsewhere, remediation increasingly requires switching teams.
But these are not political teams. They are ontological commitments.
Ontologies are not held like opinions. They are held like grammar. You do not argue someone out of them. At best, you expose their costs. At worst, you force others to operate within yours by disqualifying alternatives.
Retributive justice does the latter.
5. What This Means (Without Offering a Fix)
Justice systems are not broken. They are optimised. They are optimised for closure, manageability, and the appearance of neutrality. Fairness supplies the rhetoric. Commensurability supplies the mathematics. Together, they convert contestable metaphysical wagers into procedural common sense.
That optimisation has costs:
Disagreements about value become illegible
Alternative ontologies become unplayable
Dissent becomes pathology
Foundations disappear from view
If justice feels fair, it is because the comparisons required to question it were never permitted.
Ontology as Pre-emptive Gatekeeping
None of this requires conspiracy.
Institutions do not consciously enforce ontologies. They do not need to.
They educate them. Normalise them. Proceduralise them. Then treat their rejection as irrationality.
By the time justice is invoked, the following have already been installed as reality:
That persons persist over time in morally relevant ways
That agents meaningfully choose under conditions that count
That harms can be compared and offset
That responsibility can be localised
That disagreement beyond a point is unreasonable
None of these are discovered. All are rehearsed.
A law student learns that ‘the reasonable person’ is a construct. By year three, they use it fluently. It no longer feels constructed.
This is not indoctrination. It is fluency.
And fluency is how ontologies hide.
By the time an alternative appears – episodic selfhood, incommensurable harm, distributed agency – it does not look like metaphysics. It looks like confusion.
Rationality as Border Control
The system does not say: we reject your ontology.
It says: that’s not how the world works.
Or worse: you’re being unreasonable.
Ontological disagreement is reframed as a defect in the person. And defects do not need answers. They need management.
This is why some arguments feel impossible to have. One ontology has been naturalised into common sense. The other has been reclassified as error.
The Final Irony
The more fragile the foundations, the more aggressively they must be defended as self-evident.
Free will is taught as obvious.
Fairness is invoked as perceptual.
Responsibility is treated as observable.
Incommensurability is treated as sabotage.
Not because the system is confident.
Because it cannot afford not to be.
The Point
Justice does not merely rely on asserted ontologies. It expends enormous effort ensuring they never appear asserted at all.
By the time the cards are dealt, the rules have already been mistaken for reality. That is the felt beneath the table. Invisible. Essential. Doing all the work. And if you want to challenge justice meaningfully, you do not start with outcomes. You start by asking:
What comparisons are we being asked to accept as natural? And what happens to those who refuse?
Most people never make that move. Not because it is wrong. But because by the time you notice the game is rigged, you are already fluent in its rules. And fluency feels like truth.
Final Word
Why write these assessments? Why care?
With casinos, like cricket, we understand something fundamental: these are games. We can learn the rules. We can decide whether to play. We can walk away.
Justice is different. Justice is not opt-in. It is imposed. You do not get to negotiate the rules, the scoring system, or the house assumptions about what counts as a move. Once you are inside, even dissent must be expressed in the system’s own grammar. Appeals do not question the game; they replay it under slightly altered conditions.
You may contest the outcome. You may plead for leniency. You may argue fairness. You may not ask why chips are interchangeable with lives, why losses must be comparable, or why refusing comparison itself counts as misconduct.
Imagine being forced into a casino. Forced to play. Forced to stake things you do not believe are wagerable. Then told, when you object, that the problem is not the game, but your attitude toward it.
That is why these assessments matter. Not to declare justice illegitimate. Not to offer a fix. But to make visible the rules that pretend not to be rules at all. Because once you mistake fluency for truth, the house no longer needs to rig the game.
Now that A Language Insufficiency Hypothesis has been put to bed — not euthanised, just sedated — I can turn to the more interesting work: instantiating it. This is where LIH stops being a complaint about words and starts becoming a problem for systems that pretend words are stable enough to carry moral weight.
What follows is not a completed theory, nor a universal schema. It’s a thinking tool. A talking point. A diagram designed to make certain assumptions visible that are usually smuggled in unnoticed, waved through on the strength of confidence and tradition.
The purpose of this diagram is not to redefine justice, rescue it, or replace it with something kinder. It is to show how justice is produced. Specifically, how retributive justice emerges from a layered assessment process that quietly asserts ontologies, filters encounters, applies normative frames, and then closes uncertainty with confidence.
Audio: NotebookLM summary podcast of this topic.
Most people are willing to accept, in the abstract, that justice is “constructed”. That concession is easy. What is less comfortable is seeing how it is constructed — how many presuppositions must already be in place before anything recognisable as justice can appear, and how many of those presuppositions are imposed rather than argued for.
The diagram foregrounds power, not as a conspiracy or an optional contaminant, but as an ambient condition. Power determines which ontologies are admissible, which forms of agency count, which selves persist over time, which harms are legible, and which comparisons are allowed. It decides which metaphysical configurations are treated as reasonable, and which are dismissed as incoherent before the discussion even begins.
Justice, in this framing, is not discovered. It is not unearthed like a moral fossil. It is assembled. And it is assembled late in the process, after ontology has been assumed, evaluation has been performed, and uncertainty has been forcibly closed.
This does not mean justice is fake. It means it is fragile. Far more fragile than its rhetoric suggests. And once you see that fragility — once you see how much is doing quiet, exogenous work — it becomes harder to pretend that disagreements about justice are merely disagreements about facts, evidence, or bad actors. More often, they are disagreements about what kind of world must already be true for justice to function at all.
I walk through the structure and logic of the model below. The diagram is also available as a PDF, because if you’re going to stare at machinery, you might as well be able to zoom in on the gears.
Why Retributive Justice (and not the rest of the zoo)
Before doing anything else, we need to narrow the target.
“Justice” is an infamously polysemous term. Retributive, restorative, distributive, procedural, transformative, poetic, cosmic. Pick your flavour. Philosophy departments have been dining out on this buffet for centuries, and nothing useful has come of letting all of them talk at once.
This is precisely where LIH draws a line.
The Language Insufficiency Hypothesis is not interested in pedestrian polysemy — cases where a word has multiple, well-understood meanings that can be disambiguated with minimal friction. That kind of ambiguity is boring. It’s linguistic weather.
What LIH is interested in are terms that appear singular while smuggling incompatible structures. Words that function as load-bearing beams across systems, while quietly changing shape depending on who is speaking and which assumptions are already in play.
“Justice” is one of those words. But it is not usefully analysable in the abstract.
So we pick a single instantiation: Retributive Justice.
Why?
Because retributive justice is the most ontologically demanding and the most culturally entrenched. It requires:
a persistent self
a coherent agent
genuine choice
intelligible intent
attributable causation
commensurable harm
proportional response
In short, it requires everything to line up.
If justice is going to break anywhere, it will break here.
Retributive justice is therefore not privileged in this model. It is used as a stress test.
The Big Picture: Justice as an Engine, Not a Discovery
The central claim of the model is simple, and predictably unpopular:
Justice is not discovered. It is produced.
Not invented in a vacuum, not hallucinated, not arbitrary — but assembled through a process that takes inputs, applies constraints, and outputs conclusions with an air of inevitability.
The diagram frames retributive justice as an assessment engine.
An engine has:
inputs
internal mechanisms
thresholds
failure modes
and outputs
It does not have access to metaphysical truth. It has access to what it has been designed to process.
The justice engine takes an encounter — typically an action involving alleged harm — and produces two outputs:
Desert (what is deserved),
Responsibility (to whom it is assigned).
Everything else in the diagram exists to make those outputs possible.
The Three Functional Layers
The model is organised into three layers. These are not chronological stages, but logical dependencies. Each layer must already be functioning for the next to make sense.
1. The Constitutive Layer
(What kind of thing a person must already be)
This layer answers questions that are almost never asked explicitly, because asking them destabilises the entire process.
What counts as a person?
What kind of self persists over time?
What qualifies as an agent?
What does it mean to have agency?
What is a choice?
What is intent?
Crucially, these are not empirical discoveries made during assessment. They are asserted ontologies.
The system assumes a particular configuration of selfhood, agency, and intent as a prerequisite for proceeding at all. Alternatives — episodic selves, radically distributed agency, non-volitional action — are not debated. They are excluded.
This is the first “happy path”.
If you do not fit the assumed ontology, you do not get justice. You get sidelined into mitigation, exception, pathology, or incoherence.
2. The Encounter Layer
(What is taken to have happened)
This layer processes the event itself:
an action
resulting harm
causal contribution
temporal framing
contextual conditions
motive (selectively)
This is where the rhetoric of “facts” tends to dominate. But the encounter is never raw. It is already shaped by what the system is capable of seeing.
Causation here is not metaphysical causation. It is legible causation. Harm is not suffering. It is recognisable harm. Context is not total circumstance. It is admissible context.
Commensurability acts as a gatekeeper between encounter and evaluation: harms must be made comparable before they can be judged. Anything that resists comparison quietly drops out of the pipeline.
3. The Evaluative Layer
(How judgment is performed)
Only once ontology is assumed and the encounter has been rendered legible does evaluation begin:
proportionality
accountability
normative ethics
fairness (claimed)
reasonableness
bias (usually acknowledged last, if at all)
This layer presents itself as the moral heart of justice. In practice, it is the final formatting pass.
Fairness is not discovered here. It is declared. Reasonableness does not clarify disputes. It narrows the range of acceptable disagreement. Bias is not eliminated. It is managed.
At the end of this process, uncertainty is closed.
That closure is the moment justice appears.
Why Disagreement Fails Before It Starts
At this point, dissent looks irrational.
The system has:
assumed an ontology
performed an evaluation
stabilised the narrative through rhetoric
and produced outputs with institutional authority
To object now is not to disagree about evidence. It is to challenge the ontology that made assessment possible in the first place.
And that is why so many justice debates feel irresolvable.
They are not disagreements within the system. They are disagreements about which system is being run.
LIH explains why language fails here. The same words — justice, fairness, responsibility, intent — are being used across incompatible ontological commitments. The vocabulary overlaps; the worlds do not.
The engine runs smoothly. It just doesn’t run the same engine for everyone.
Where This Is Going
With the structure in place, we can now do the slower work:
unpacking individual components
tracing where ontological choices are asserted rather than argued
showing how “reasonableness” and “fairness” operate as constraint mechanisms
and explaining why remediation almost always requires a metaphysical switch, not better rhetoric
Justice is not broken. It is doing exactly what it was built to do.
That should worry us more than if it were merely malfunctioning.
This essay is already long, so I’m going to stop here.
Not because the interesting parts are finished, but because this is the point at which the analysis stops being descriptive and starts becoming destabilising.
The diagram you’ve just walked through carries a set of suppressed footnotes. They don’t sit at the margins because they’re trivial; they sit there because they are structurally prior. Each one represents an ontological assertion the system quietly requires in order to function at all.
By my count, the model imposes at least five such ontologies. They are not argued for inside the system. They are assumed. They arrive pre-installed, largely because they are indoctrinated, acculturated, and reinforced long before anyone encounters a courtroom, a jury, or a moral dilemma.
Once those ontologies are fixed, the rest of the machinery behaves exactly as designed. Disagreement downstream is permitted; disagreement upstream is not.
In a follow-up essay, I’ll unpack those footnotes one by one: where the forks are, which branch the system selects, and why the alternatives—while often coherent—are rendered unintelligible, irresponsible, or simply “unreasonable” once the engine is in motion.
That’s where justice stops looking inevitable and starts looking parochial.
And that’s also where persuasion quietly gives up.
Written by Bry Willis and ChatGPT 5.2 after a couple of days of back and forth
I’ve been working on A Language Insufficiency Hypothesis since 2018. At least, that’s the polite, CV-friendly version. The truer account is that it’s been quietly fermenting since the late 1970s, back when I was still trapped in primary school and being instructed on how the world supposedly worked.
Social Studies. Civics. Law. The whole civic catechism. I remember being taught about reasonable persons and trial by a jury of one’s peers, and I remember how insistently these were presented as fair solutions. Fairness was not argued for. It was asserted, with the weary confidence of people who think repetition counts as justification.
I didn’t buy it. I still don’t. The difference now is that I have a hypothesis with some explanatory power instead of a vague sense that the adults were bluffing.
Audio: NotebookLM summary podcast of this topic.
I’ve always been an outsider. Eccentric, aloof, l’étranger if we’re feeling theatrical. It never particularly troubled me. Outsiders are often tolerated, provided they remain decorative and non-contagious. Eye rolls were exchanged on both sides. No harm done.
But that outsider position had consequences. It led me, even then, to ask an awkward question: Which peers? Not because I thought I was superior, but because I was plainly apart. How exactly was I meant to be judged by my peers when no one else occupied anything like my perspective?
Later, when I encountered the concept of fundamental attribution bias, it felt less like a revelation and more like confirmation. A peer-based system assumes not just similarity of circumstance, but similarity of interpretation. That assumption was dead on arrival.
Then there were reasonable persons. I was assured they existed. I was assured judges were trained to embody them. I had never met one. Even as a teenager, I found the idea faintly comical. Judges, I was told, were neutral, apolitical, and dispassionate. Writing this now from the United States, one hardly needs to belabour the point. But this wasn’t prescience. It was intuition. The smell test failed decades ago.
Before LIH had a name, I called these things weasel words. I still do, as a kind of shorthand. Terms like fair, reasonable, accountable, appropriate. Squishy concepts that do serious institutional work whilst remaining conveniently undefinable. Whether one wants to label them Contestables or Fluids is less important than recognising the space they occupy.
That space sits between Invariables, things you can point to without dispute, and Ineffables, where language more or less gives up. Communication isn’t binary. It isn’t ‘works’ or ‘doesn’t’. It’s a gradient. A continuous curve from near-certainty to near-failure.
Most communication models quietly assume a shared ontology. If misunderstanding occurs, the remedy is more explanation, more context, more education. What never sat right with me, even as a child, was that this only works when the disagreement is superficial. The breaking point is ontological.
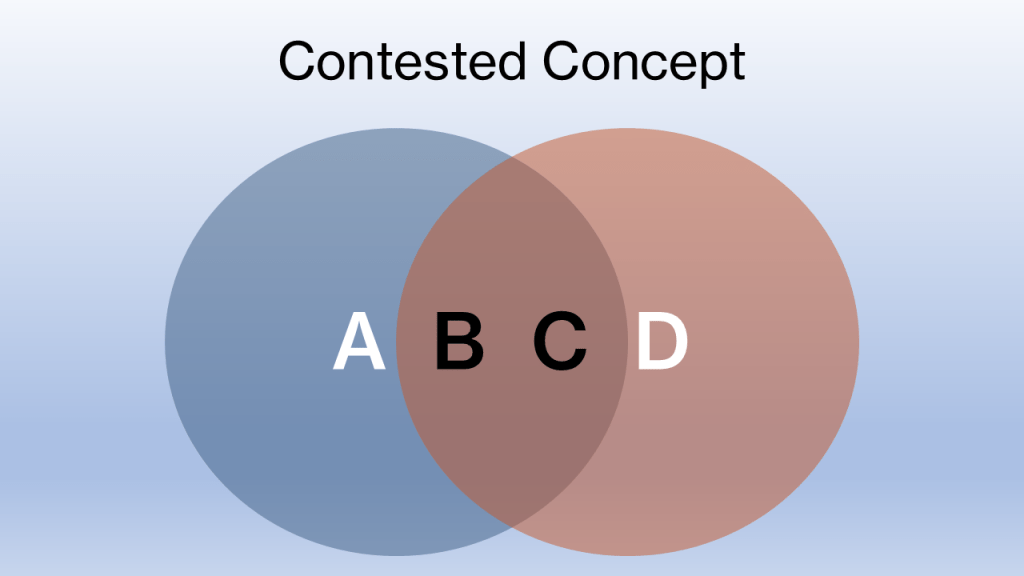
If one person believes a term means {A, B, C} and another believes it means {B, C, D}, the overlap creates a dangerous illusion of agreement. The disagreement hides in the margins. A and D don’t merely differ. They are often irreconcilable.
Image: Venn diagramme of a contested concept. Note: This is illustrative and not to scale
Fairness is a reliable example. One person believes fairness demands punishment, including retributive measures. Another believes fairness permits restoration but rejects retribution, citing circumstance, history, or harm minimisation. Both invoke fairness sincerely. The shared language conceals the conflict.
When such disputes reach court, they are not resolved by semantic reconciliation. They are resolved by authority. Power steps in where meaning cannot. This is just one illustration. There are many.
I thought it worth sharing how LIH came about, if only to dispel the notion that it’s a fashionable response to contemporary politics. It isn’t. It’s the slow crystallisation of a long-standing intuition: that many of our most cherished concepts don’t fail because we misuse them, but because they were never capable of doing the work we assigned to them.
How retribution stays upright by not being examined
There is a persistent belief that our hardest disagreements are merely technical. If we could stop posturing, define our terms, and agree on the facts, consensus would emerge. This belief survives because it works extremely well for birds and tables.
It fails spectacularly for justice.
Audio: NotebookLM summary podcast of this topic.
The Language Insufficiency Hypothesis (LIH) isn’t especially interested in whether people disagree. It’s interested in how disagreement behaves under clarification. With concrete terms, clarification narrows reference. With contested ones, it often fractures it. The more you specify, the more ontologies appear.
Justice is the canonical case.
Retributive justice is often presented as the sober, adult conclusion. Not emotional. Not ideological. Just what must be done. In practice, it is a delicately balanced structure built out of other delicately balanced structures. Pull one term away and people grow uneasy. Pull a second and you’re accused of moral relativism. Pull a third and someone mentions cavemen.
Let’s do some light demolition. I created a set of 17 Magic: The Gathering-themed cards to illustrate various concepts. Below are a few. A few more may appear over time.
Card One: Choice
Image: MTG: Choice – Enchantment
The argument begins innocently enough:
They chose to do it.
But “choice” here is not an empirical description. It’s a stipulation. It doesn’t mean “a decision occurred in a nervous system under constraints.” It means a metaphysically clean fork in the road. Free of coercion, history, wiring, luck, trauma, incentives, or context.
That kind of choice is not discovered. It is assumed.
Pointing out that choices are shaped, bounded, and path-dependent does not refine the term. It destabilises it. Because if choice isn’t clean, then something else must do the moral work.
Enter the next card.
Card Two: Agency
Image: MTG: Agency – Creature – Illusion
Agency is wheeled in to stabilise choice. We are reassured that humans are agents in a morally relevant sense, and therefore choice “counts”.
Counts for what, exactly, is rarely specified.
Under scrutiny, “agency” quietly oscillates between three incompatible roles:
a descriptive claim: humans initiate actions
a normative claim: humans may be blamed
a metaphysical claim: humans are the right kind of cause
These are not the same thing. Treating them as interchangeable is not philosophical rigour. It’s semantic laundering.
But agency is emotionally expensive to question, so the discussion moves on briskly.
Card Three: Responsibility
Image: MTG: Responsibility – Enchantment – Curse
Responsibility is where the emotional payload arrives.
To say someone is “responsible” sounds administrative, even boring. In practice, it’s a moral verdict wearing a clipboard.
Watch the slide:
causal responsibility
role responsibility
moral responsibility
legal responsibility
One word. Almost no shared criteria.
By the time punishment enters the picture, “responsibility” has quietly become something else entirely: the moral right to retaliate without guilt.
At which point someone will say the magic word.
Card Four: Desert
Image: MTG: Desert – Instant
Desert is the most mystical card in the deck.
Nothing observable changes when someone “deserves” punishment. No new facts appear. No mechanism activates. What happens instead is that a moral permission slip is issued.
Desert is not found in the world. It is declared.
And it only works if you already accept a very particular ontology:
robust agency
contra-causal choice
a universe in which moral bookkeeping makes sense
Remove any one of these and desert collapses into what it always was: a story we tell to make anger feel principled.
Which brings us, finally, to the banner term.
Card Five: Justice
Image: MTG: Justice – Enchantment
At this point, justice is invoked as if it were an independent standard hovering serenely above the wreckage.
It isn’t.
“Justice” here does not resolve disagreement. It names it.
Retributive justice and consequentialist justice are not rival policies. They are rival ontologies. One presumes moral balance sheets attached to persons. The other presumes systems, incentives, prevention, and harm minimisation.
Both use the word justice.
That is not convergence. That is polysemy with a body count.
Why clarification fails here
This is where LIH earns its keep.
With invariants, adding detail narrows meaning. With terms like justice, choice, responsibility, or desert, adding detail exposes incompatible background assumptions. The disagreement does not shrink. It bifurcates.
This is why calls to “focus on the facts” miss the point. Facts do not adjudicate between ontologies. They merely instantiate them. If agency itself is suspect, arguments for retribution do not fail empirically. They fail upstream. They become non sequiturs.
This is also why Marx remains unforgivable to some. “From each according to his ability, to each according to his need” isn’t a policy tweak. It presupposes a different moral universe. No amount of clarification will make it palatable to someone operating in a merit-desert ontology.
The uncomfortable conclusion
The problem is not that we use contested terms. We cannot avoid them.
The problem is assuming they behave like tables.
Retributive justice survives not because it is inevitable, but because its supporting terms are treated as settled when they are anything but. Each card looks sturdy in isolation. Together, they form a structure that only stands if you agree not to pull too hard.
LIH doesn’t tell you which ontology to adopt.
It tells you why the argument never ends.
And why, if someone insists the issue is “just semantic”, they’re either confused—or holding the deck.
As the publication date of A Language Insufficiency Hypothesis (LIH) draws nearer, I feel it’s a good time to promote it (obviously) and to introduce some of the problems it uncovers – including common misperceptions I’ve already heard. Through this feedback, I now understand some of the underlying structural limitations that I hadn’t considered, but this only strengthens my position. As I state at the start of the book, the LIH isn’t a cast-in-stone artefact. Other discoveries will inevitably be made. For now, consider it a way to think about the deficiencies of language, around which remediation strategies can be developed.
Audio: NotebookLM summary podcast of this content.
Let’s clear the undergrowth first. The Language Insufficiency Hypothesis is not concerned with everyday ambiguity, garden-variety polysemy, or the sort of misunderstandings that vanish the moment someone bothers to supply five seconds of context. That terrain is already well-mapped, thoroughly fenced, and frankly dull.
Take the classic sort of example wheeled out whenever someone wants to sound clever without doing much work:
‘I made a 30-foot basket’.
Video: a woman making a large basket
If you’re a basketweaver, you picture an absurdly large basket and quietly question the maker’s life choices. If you’re watching basketball, you hear ‘score’. If you’re anywhere near the context in which the sentence was uttered, the meaning is obvious. If it isn’t, the repair cost is trivial. Add context, move on, live your life.
Language did not fail here. It merely waited for its coat. This is not the sort of thing the LIH loses sleep over.
The Groucho Marx Defence, or: Syntax Is Not the Problem
Logicians and armchair philosophers love to reach for jokes like Groucho Marx’s immortal line:
‘I shot an elephant in my pyjamas. Why it was wearing my pyjamas, I’ll never know’.
Video: A man and elephant in pyjamas (no sound)
Yes, very funny. Yes, the sentence allows for a syntactic misreading. No, nobody actually believes the elephant was lounging about in striped silk. The humour works precisely because the “wrong” parse is momentarily entertained and instantly rejected.
Again, language is not insufficient here. It’s mischievous. There’s a difference.
If the LIH were worried about this sort of thing, its ambitions would be indistinguishable from an undergraduate logic textbook with better branding.
Banks, Rivers, and the Myth of Constant Confusion
Likewise, when someone in a city says, ‘I went to the bank’, no sane listener imagines them strolling along a riverbank, unless they are already knee-deep in pastoral fantasy or French tourism brochures. Context does the heavy lifting. It almost always does.
Video: Rare footage of me trying to withdraw funds at my bank (no sound)
This is not a crisis of meaning. This is language functioning exactly as advertised.
Where the Trouble Actually Starts: Contestables
The LIH begins where these tidy examples stop being helpful. It concerns itself with Contestables: terms like truth, freedom, justice, fairness, harm, equality. Words that look stable, behave politely in sentences, and then detonate the moment you ask two people what they actually mean by them. These are not ambiguous in the casual sense. They are structurally contested.
In political, moral, and cultural contexts, different groups use the same word to gesture at fundamentally incompatible conceptual frameworks, all while assuming a shared understanding that does not exist. The conversation proceeds as if there were common ground, when in fact there is only overlap in spelling.
That’s why attempts to ‘define’ these terms so often collapse into accusation:
That’s not what freedom means. That’s not real justice. You’re redefining truth.
No, the definitions were never shared in the first place. The disagreement was smuggled in with the noun.
‘Just Ignore the Word’ Is Not a Rescue
A common response at this point is to suggest that we simply bypass the troublesome term and discuss the concrete features each party associates with it. Fine. Sensible. Often productive. But notice what this manoeuvre concedes. It does not save the term. It abandons it.
If meaningful discussion can only proceed once the word is set aside and replaced with a list of clarifications, constraints, examples, and exclusions, then the word has already failed at its primary job: conveying shared meaning. This is precisely the point the LIH is making.
The insufficiency is not that language is vague, or flexible, or context-sensitive. It’s that beyond a certain level of conceptual complexity, language becomes a confidence trick. It gives us the feeling of agreement without the substance, the appearance of communication without the transaction.
At that point, words don’t merely underperform. They mislead.
It’s finally arrived, and now I have to review it.
I’ve published books before. In fact, this one is number nine – cue the Beatles’ White Album. I was nervous as I released my first fiction as Ridley Park, and I released three more before I released my first nonfiction as myself. But this one means the most to me.
Audio: NotebookLM summary podcast of this content – sort of.
I am well aware that artists tend to say that about each piece of work as it is born into the world, but this one actually started before any of the other ones. About a year ago, it had twice as many pages, and I’ve been whittling it down to 132 pages. At the same time, I am trying to cut the fat, new meat appears, and I have to decide how to treat it. In this social media world, I can instantiate some of it through this lens. At some point, I may publish a second edition. I may even produce a version that incorporates several of my ideas with connective tissue.
My near-term goal is to review this page-by-page for mistakes – misstatements – and to see how it lays out on the page. Obviously, I produce my work on a computer – a PC. I tend to write in Microsoft Word and format in InDesign. I output to PDF, as required by printers. Although I print pages for review, there is still something different about a physical, bound book. I’ve even printed it in a folded booklet style, which gets mostly there, but it’s still deficient.
This is an announcement, not a promotion. I’m not trying to pad out an entry, but I wanted to share. I’ll end here.