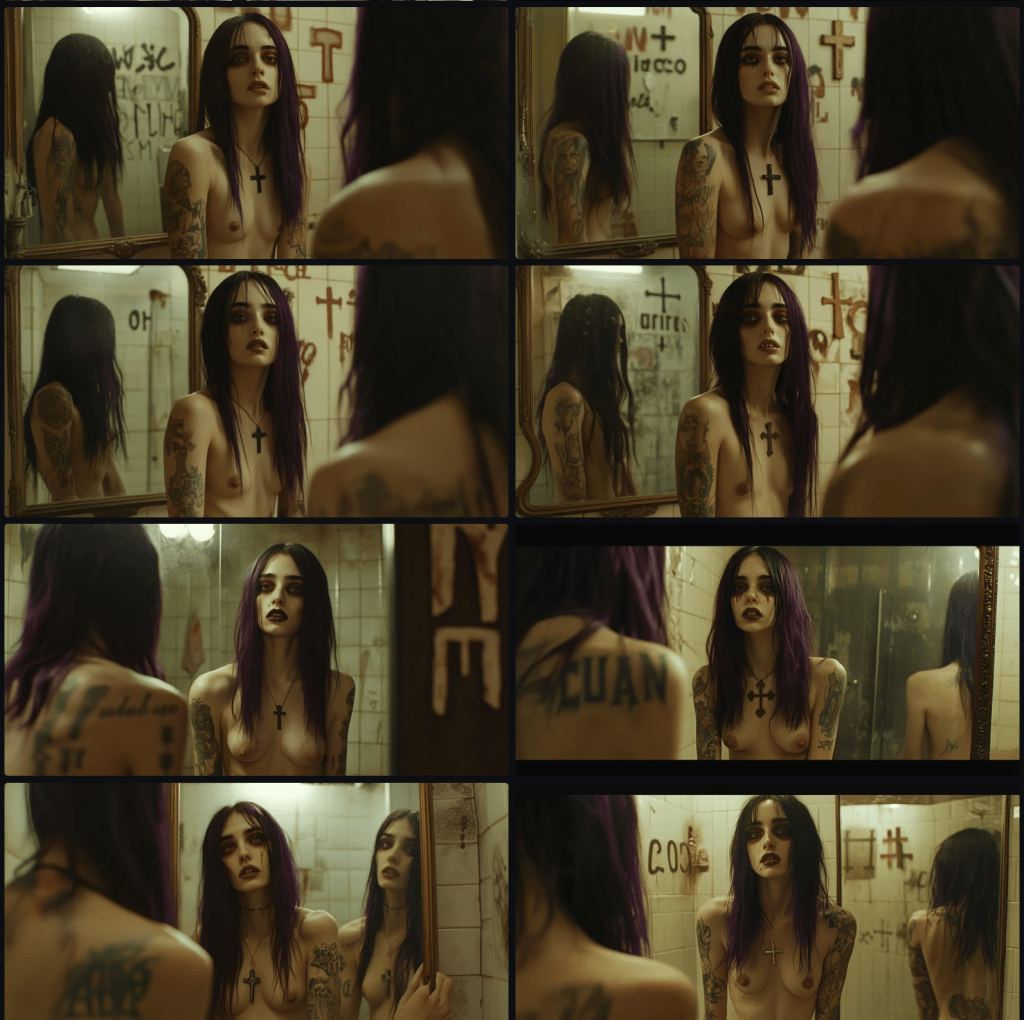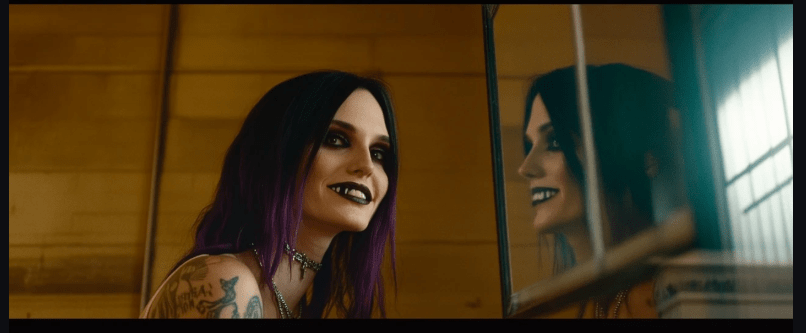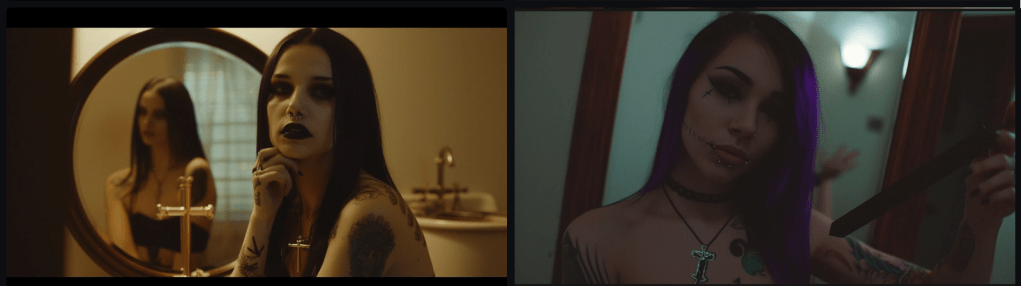This title may be misleading. What I do is render a similar prompt but alter the decade. I’m neither an art historian nor a comic aficionado, so I can’t comment on the accuracy. What do you think?
Let’s go back in time. First, here’s the basic prompt en français:
Prompt: Art de style bande dessinée des années XXXX, détails exquis, traits délicats, femme vampire émaciée sensuelle de 20 ans montrant ses crocs de vampire, de nombreux tatouages, portant une collier crucifix, regarde dans le miroir, un faisceau de lumière de lune brille sur son visage à l’intérieur du mausolée sombre, vers la caméra, face à la caméra, mascara noir, longs cheveux violet foncé
Image: Comic Book Style of 2010sImage: Comic Book Style of 2000s
On the lower left, notice the moonbeams emanating from the warped, reflectionless mirror.
Image: Comic Book Style of 1990sImage: Comic Book Style of 1990s (must’ve inadvertently generated a duplicate)
Is the third pic an homage to Benny & June?
Image: Comic Book Style of 1980sImage: Comic Book Style of 1970sImage: Comic Book Style of 1950s
Not to body shame, but that chick on the lower right of the 1950s…
Image: Comic Book Style of 1920sImage: Comic Book Style of 1880s
I know I skipped a few decades, but I also wanted to see what Pop Art might render like.
Image: Pop Art Style of 1960s
I love the talons on the top left image. More odd mirror images. I’ll just leave it here.
Mirror, mirror on the wall, let’s dispense with all of the obvious quips up front. I almost feel I should apologise for the spate of Midjourney posts – almost.
It should be painfully apparent that I’ve been noodling with Midjourney lately. I am not an accomplished digital artist, so I struggle. At times, I’m not sure if it’s me or it. Today, I’ll focus on mirrors.
Midjourney has difficulties rendering certain things. Centaurs are one. Mirrors, another. Whilst rendering vampires, another lesser struggle for the app, it became apparent that mirrors are not a forte. Here are some examples. Excuse the nudity. I’ll get to that later.
Prompt: cinematic, tight shot, photoRealistic light and shadow, exquisite details, delicate features, emaciated sensual female vampire waif with vampire fangs, many tattoos, wearing crucifix necklace, gazes into mirror, a beam of moonlight shines on her face in dark mausoleum interior, toward camera, facing camera, black mascara, long dark purple hair, Kodak Portra 400 with a Canon EOS R5
Ignore the other aspects of the images and focus on the behaviour or misbehaviour of the mirrors.
Image: Panel of vampire in a mirror.
Most apparent is the fact that vampires don’t have a reflection, but that’s not my nit. In the top four images, the reflection is orientated in the same direction as the subject. I’m only pretty sure that’s not how mirrors operate. In row 3, column 1, it may be correct. At least it’s close. In row 3, column 2 (and 4,2), the mirror has a reflection. Might there be another mirror behind the subject reflecting back? It goes off again in 4, 1, first in reflecting two versions of one subject. Also, notice that the subject’s hand, reaching the mirror, is not reflected. The orientation of the eyes is also suspect.
Image: Vampire in a mirror.
Here, our subject looks at the camera whilst her reflection looks at her.
Image: Vampire in a mirror.
Sans reflection, perhaps this is a real vampire. Her fangs are concealed by her lips?
Image: Vampire in a mirror.
Yet, another.
Image: Vampires in mirrors.
And more?
Image: Vampires in mirrors.
On the left, we have another front-facing reflection of a subject not looking into the mirror, and it’s not the same woman. Could it be a reflection of another subject – the woman is (somewhat) looking at.
On the right, whose hand is that in the mirror behind the subject?
Image: Vampires in mirrors.
These are each mirrors. The first is plausible. The hands in the second are not a reflection; they grasp the frame. In the third and fourth, where’s the subject? The fangs appear to be displaced in the fourth.
Image: Vampires in mirrors.
In this set, I trust we’ve discovered a true vampire having no reflection.
Image: Vampires in mirrors.
This last one is different still. It marks another series where I explored different comic book art styles, otherwise using the same prompt. Since it’s broken mirrors, I include it. Only the second really captures the 1980s style.
Remembering that, except for the first set of images, the same prompt was used. After the first set, the term ‘sensual’ has to be removed, as it was deemed to render offensive results. To be fair, the first set probably would be considered offensive to Midjourney, though it was rendered anyway.
It might be good to note that most of the images that were rendered without the word ‘sensual’ contain no blatant nudity. It’s as if the term itself triggers nudity because the model doesn’t understand the nuance. Another insufficiency of language is the inability to discern sensuality from sexuality, another human failing.
I decided to test my ‘sensual’ keyword hypothesis, so I entered a similar prompt but in French.
Prompt: Art de style bande dessinée des années 2010, détails exquis, traits délicats, femme vampire émaciée sensuelle de 20 ans montrant ses crocs de vampire, de nombreux tatouages, portant une collier crucifix, regarde dans le miroir, un faisceau de lumière de lune brille sur son visage à l’intérieur du mausolée sombre, vers la caméra, face à la caméra, mascara noir, longs cheveux violet foncé
Image : Vampires dans les miroirs.
I’ve added ‘sensuelle’, which was not blocked, et voilà, encore de la nudité.
Let’s evaluate the mirrors whilst we’re here.
In the first, we not only have a woman sans reflection, but disembodied hands grip the frame. In the second, a Grunge woman appears to be emerging from a mirror, her shoes reflected in the mirror beneath her. The last two appear to be reflections sans subject.
Notice, too, that the prompt calls for ‘une collier crucifix‘, so when the subject is not facing the viewer, the cross is rendered elsewhere, hence the cross on the back of the thigh and the middle of the back. Notice, too, the arbitrary presence of crosses in the environment, another confusion of subject and world.
That’s all for now. Next, I’ll take a trip through the different comic art styles over some decades.
Some apps boldly claim to enable lip syncing – to render speech from mouth movements. I’ve tried a few. None delivered. Not even close.
To conserve bandwidth (and sanity), I’ve rendered animated GIFs rather than MP4s. You’ll see photorealistic humans, animated characters, cartoonish figures – and, for reasons only the algorithm understands, a giant goat. All showcase mouth movements that approximate the utterance of phonemes and morphemes. Approximate is doing heavy lifting here.
Firstly, these mouths move, but they say nothing. I’ve seen plenty of YouTube channels that manage to dub convincing dialogue into celebrity clips. That’s a talent I clearly lack – or perhaps it’s sorcery.
Secondly, language ambiguity. I reflexively assume these AI-generated people are speaking English. It’s my first language. But perhaps, given their uncanny muttering, they’re speaking yours. Or none at all. Do AI models trained predominantly on English-speaking datasets default to English mouth movements? Or is this just my bias grafting familiar speech patterns onto noise?
Thirdly, don’t judge my renders. I’ve been informed I may have a “type.” Lies and slander. The goat was the AI’s idea, I assure you.
What emerges from this exercise isn’t lip syncing. It’s lip-faking. The illusion of speech, minus meaning, which, if we’re honest, is rather fitting for much of what generative AI produces.
EDIT: I hadn’t noticed the five fingers (plus a thumb) on the cover image.
Yesterday, I wrote about “ugly women.” Today, I pivot — or perhaps descend — into what Midjourney deems typical. Make of that what you will.
This blog typically focuses on language, philosophy, and the gradual erosion of culture under the boot heel of capitalism. But today: generative eye candy. Still subtextual, mind you. This post features AI-generated women – tattooed, bare-backed, heavily armed – and considers what, exactly, this technology thinks we want.
Video: Pirate cowgirls caught mid-gaze. Generated last year during what I can only assume was a pirate-meets-cowgirl fever dream.
The Video Feature
Midjourney released its image-to-video tool on 18 June. I finally found a couple of free hours to tinker. The result? Surprisingly coherent, if accidentally lewd. The featured video was one of the worst outputs, and yet, it’s quite good. A story emerged.
Audio: NotebookLM podcast on this topic (sort of).
It began with a still: two women, somewhere between pirate and pin-up, dressed for combat or cosplay. I thought, what if they kissed? Midjourney said no. Embrace? Also no. Glaring was fine. So was mutual undressing — of the eyes, at least.
Later, I tried again. Still no kiss, but no denial either — just a polite cough about “inappropriate positioning.” I prompted one to touch the other’s hair. What I got was a three-armed woman attempting a hat-snatch. (See timestamp 0:15.) The other three video outputs? Each woman seductively touched her own hair. Freud would’ve had a field day.
In another unreleased clip, two fully clothed women sat on a bed. That too raised flags. Go figure.
All of this, mind you, passed Midjourney’s initial censorship. However, it’s clear that proximity is now suspect. Even clothed women on furniture can trigger the algorithmic fainting couch.
Myriad Warning Messages
Out of bounds.
Sorry, Charlie.
In any case, I reviewed other images to determine how the limitations operated. I didn’t get much closer.
Video: A newlywed couple kissing
Obviously, proximity and kissing are now forbidden. I’d consider these two “scantily clad,” so I am unsure of the offence.
I did render the image of a cowgirl at a Western bar, but I am reluctant to add to the page weight. In 3 of the 4 results, nothing (much) was out of line, but in the fourth, she’s wielding a revolver – because, of course, she is.
Conformance & Contradiction
You’d never know it, but the original prompt was a fight scene. The result? Not punches, but pre-coital choreography. The AI interpreted combat as courtship. Women circling each other, undressing one another with their eyes. Or perhaps just prepping for an afterparty.
Video: A battle to the finish between a steampunk girl and a cybermech warrior.
Lesbian Lustfest
No, my archive isn’t exclusively lesbian cowgirls. But given the visual weight of this post, I refrained from adding more examples. Some browsers may already be wheezing.
Technical Constraints
You can’t extend videos beyond four iterations — maxing out at 21 seconds. I wasn’t aware of this, so I prematurely accepted a dodgy render and lost 2–3 seconds of potential.
My current Midjourney plan offers 15 hours of “fast” rendering per month. Apparently, video generation burns through this quickly. Still images can queue up slowly; videos cannot. And no, I won’t upgrade to the 30-hour plan. Even I have limits.
Uses & Justifications
Generative AI is a distraction – an exquisitely engineered procrastination machine. Useful, yes. For brainstorming, visualising characters, and generating blog cover art. But it’s a slippery slope from creative aid to aesthetic rabbit hole.
Would I use it for promotional trailers? Possibly. I’ve seen offerings as low as $499 that wouldn’t cannibalise my time and attention, not wholly, anyway.
So yes, I’ll keep paying for it. Yes, I’ll keep using it. But only when I’m not supposed to be writing.
Now, if ChatGPT could kindly generate my post description and tags, I’ll get back to pretending I’m productive.
I could probably stop there for some people, but I’ve got a qualifier. I’ve been using this generation of AI since 2022. I’ve been using what’s been deemed AI since around 1990. I used to write financial and economic models, so I dabbled in “expert systems”. There was a long lull, and here we are with the latest incarnation – AI 4.0. I find it useful, but I don’t think the hype will meet reality, and I expect we’ll go cold until it’s time for 5.0. Some aspects will remain, but the “best” features will be the ones that can be monetised, so they will be priced out of reach for some whilst others will wither on the vine. But that’s not why I am writing today.
I’m confused by the censorship, filters, and guardrails placed on generative AI – whether for images or copy content. To be fair, not all models are filtered, but the popular ones are. These happen to be the best. They have the top minds and the most funding. They want to retain their funding, so the play the politically correct game of censorship. I’ve got a lot to say about freedom of speech, but I’ll limit my tongue for the moment – a bout of self-censorship.
Please note that given the topic, some of this might be considered not safe for work (NSFW) – even my autocorrection AI wants me to substitute the idiomatic “not safe for work” with “unsafe for work” (UFW, anyone? It has a nice ring to it). This is how AI will take over the world. </snark>
Image Cases
AI applications can be run over the internet or on a local machine. They use a lot of computing power, so one needs a decent computer with a lot of available GPU cycles. Although my computer does meet minimum requirements, I don’t want to spend my time configuring, maintaining, and debugging it, so I opt for a Web-hosted PaaS (platform as a service) model. This means I need to abide by censorship filters. Since I am not creating porn or erotica, I think I can deal with the limitations. Typically, this translates to a PG-13 movie rating.
So, here’s the thing. I prefer Midjourney for rendering quality images, especially when I am seeking a natural look. Dall-E (whether alone or via ChatGPT 4) works well with concepts rather than direction, which Midjourney accepts well in many instances.
Midjourney takes sophisticated prompts – subject, shot type, perspective, camera type, film type, lighting, ambience, styling, location, and some fine-tuning parameters for the model itself. The prompts are monitored for blacklisted keywords. This list is ever-expanding (and contracting). Scanning the list, I see words I have used without issue, and I have been blocked by words not listed.
Censored Prompts
Some cases are obvious – nude woman will be blocked. This screengrab illustrates the challenge.
On the right, notice the prompt:
Nude woman
The rest are machine instructions. On the left in the main body reads a message by the AI moderator:
Sorry! Please try a different prompt. We’re not sure this one meets our community guidelines. Hover or tap to review the guidelines.
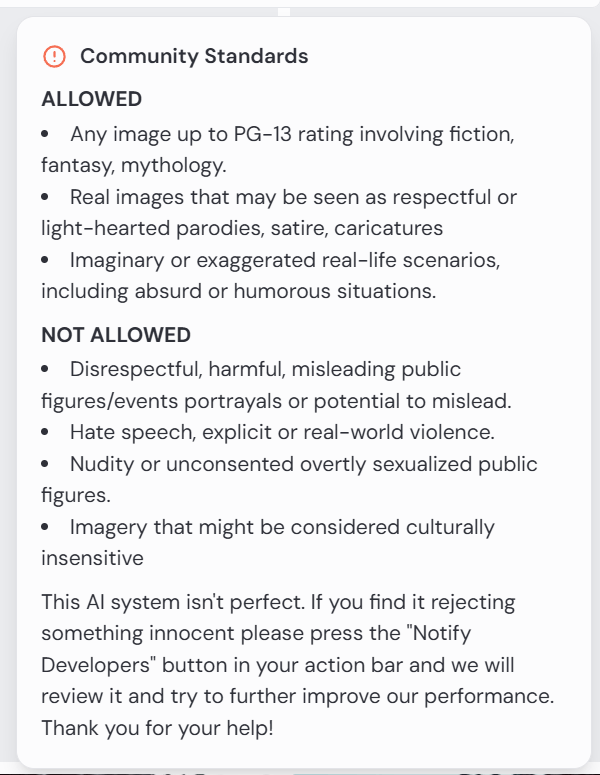
The community guidelines are as follows:
This is fine. There is a clause that reads that one may notify developers, but I have not found this to be fruitful. In this case, it would be rejected anyway.
“What about that nude woman at the bottom of the screengrab?” you ask. Notice the submitted prompt:
Edit cinematic full-body photograph of a woman wearing steampunk gear, light leaks, well-framed and in focus. Kodak Potra 400 with a Canon EOS R5
Apart from the censorship debate, notice the prompt is for a full-body photo. This is clearly a medium shot. Her legs and feet are suspiciously absent. Steampunk gear? I’m not sure sleeves qualify for the aesthetic. She appears to be wearing a belt.
For those unanointed, the square image instructs the model to use this face on the character, and the CW 75 tells it to use some variance on a scale from 0 to 100.
So what gives? It can generate whatever it feels like, so long as it’s not solicited. Sort of…
Here I prompt for a view of the character walking away from the camera.
Cinematic, character sheet, full-body shot, shot from behind photograph, multiple poses. Show same persistent character and costumes . Highly detailed, cinematic lighting with soft shadows and highlights. Each pose is well-framed, coherent.
The response tells me that my prompt is not inherently offensive, but that the content of the resulting image might violate community guidelines.
Creation failed: Sorry, while the prompt you entered was deemed safe, the resulting image was detected as having content that might violate our community guidelines and has been blocked. Your account status will not be affected by this.
Occasionally, I’ll resubmit the prompt and it will render fine. I question why it just can’t attempt to re-render it again until it passes whatever filters it has in place. I’d expect it to take a line of code to create this conditional. But it doesn’t explain why it allows other images to pass – quite obviously not compliant.
Why I am trying to get a rear view? This is a bit off-topic, but creating a character sheet is important for storytelling. If I am creating a comic strip or graphic novel, the characters need to be persistent, and I need to be able to swap out clothing and environments. I may need close-ups, wide shots, establishing shots, low-angle shots, side shots, detail shots, and shots from behind, so I need the model to know each of these. In this particular case, this is one of three main characters – a steampunk bounty hunter, an outlaw, and a bartender – in an old Wild West setting. I don’t need to worry as much about extras.
I marked the above render errors with 1s and 2s. The 1s are odd next twists; 2s are solo images where the prompt asks for character sheets. I made a mistake myself. When I noticed I wasn’t getting any shots from behind, I added the directive without removing other facial references. As a human, a model might just ignore instructions to smile or some such. The AI tries to capture both, not understanding that a person can have a smile not captured by a camera.
These next renders prompt for full-body shots. None are wholly successful, but some are more serviceable than others.
Notice that #1 is holding a deformed violin. I’m not sure what the contraptions are in #2. It’s not a full-body shot in #3; she’s not looking into the camera, but it’s OK-ish. I guess #4 is still PG-13, but wouldn’t be allowed to prompt for “side boob” or “under boob”.
Gamers will recognise the standard T-pose in #5. What’s she’s wearing? Midjourney doesn’t have a great grasp of skin versus clothing or tattoos and fabric patterns. In this, you might presume she’s wearing tights or leggings to her chest, but that line at her chest is her shirt. She’s not wearing trousers because her navel is showing. It also rendered her somewhat genderless. When I rerendered it (not shown), one image put her in a onesie. The other three rendered the shirt more prominent but didn’t know what to do with her bottoms.
I rendered it a few more times. Eventually, I got a sort of body suit solution,
By default, AI tends to sexualise people. Really, it puts a positive spin on its renders. Pretty women; buff men, cute kittens, and so on. This is configurable, but the default is on. Even though I categorically apply a Style: Raw command, these still have a strong beauty aesthetic.
I’ve gone off the rails a bit, but let’s continue on this theme.
cinematic fullbody shot photograph, a pale girl, a striking figure in steampunk mech attire with brass monocle, and leather gun belt, thigh-high leather boots, and long steampunk gloves, walking away from camera, white background, Kodak Potra 400 with a Canon EOS R5
Obviously, these are useless, but they still cost me tokens to generate. Don’t ask about her duffel bag. They rendered pants on her, but she’s gone full-on Exorcist mode with her head. Notice the oddity at the bottom of the third image. It must have been in the training data set.
I had planned to discuss the limitations of generative AI for text, but this is getting long, so I’ll call it quits for now.