
Main event
I’m an active AI user. It’s no secret. My top uses are research and enquiry, but it is instrumental in my review and revision process.
I am trying to wrap up my latest manuscript. I’m about 5 revisions through, so I felt I was finally in a position to check for cracks and missing elements, as well as the strength of my overall position and approach. It’s not a good idea to simply prompt, ‘What do you think about this?’
I’d tried prompts as simple as, ‘Act as a referee and be adversarial against this piece’ or ‘I got this from somewhere, and I want a critique’. These approaches shield you from AI’s programmed sycophantic tendencies. But they aren’t enough. You still need to create guidelines and guardrails, which include orientating the AI; otherwise, they will likely go off the reservation.
This is the actual prompt I last employed to various LLMs:
The attached is a complete development draft of Architecture of Willing, a philosophical monograph arguing that the vocabulary of will, intent, motive, choice, decision, and related terms operates through a two-stage grammatical mechanism – compression of action-patterns into portable nouns, followed by inversion of those nouns into apparent upstream authors of the very patterns from which they were abstracted. The book calls this mechanism authoring displacement and uses it to argue that retributive desert cannot be stably grounded in the vocabulary on which it depends.
The book is deliberately diagnostic rather than prescriptive. It does not propose a replacement psychology, a reformed legal code, or a new theory of agency. It refuses to settle the traditional free-will debate on either side. These refusals are intentional and are argued for within the text.
What I am asking for is a critical engagement from a position of maximum philosophical resistance. Specifically:
The book rests on a claim about what retributive practice requires – namely, a stable inward authoring source capable of making suffering genuinely owed rather than merely institutionally imposed. If that characterisation of retributivism’s requirements is wrong, or if it applies only to unsophisticated versions while leaving the strongest contemporary defences untouched, the central argument is significantly weakened. I would like to know whether that is the case, and if so, where exactly the book’s account of retributivism’s commitments fails to engage its best defenders.
More broadly: the book is a diagnosis of grammar. The question I want pressed is whether a grammatical diagnosis can do the normative work the book needs it to do – whether there is a gap between ‘this noun cannot stably support the load placed on it’ and ‘therefore practices depending on this noun are normatively unjustified’. If there is such a gap, what would close it, and does the book close it?
Please do not soften objections in the direction of ‘this is a good book with some gaps’. If the argument is unsound, say so and say where. If it is sound against some targets but not others, identify the targets it misses. The manuscript has already received generous assessments; what it needs now is the strongest case against it.
Of course, this prompt is specific to me and my project, but one may feel free to use it as a model for similar purposes.
Among the gaps returned were arguments I had not been aware of. In fact, in a couple of places, I had already cited authors, but the AI returned additional books or essays by the same people. In other cases, it offered material by authors I hadn’t considered. Obviously, I am interested in creating solid, watertight arguments, so this only helps my case.
For this project, my LLMs of choice have been Claude, ChatGPT, Gemini, Grok, and Kimi K2. I used Perplexity, Mistral, DeepSeek, and Z.ai GLM in earlier iterations.
Peer review
Another application is to take the critique output from one LLM into another with a prompt to evaluate the critique. My modus operandi here is to pick a ‘master’ LLM – typically in a Claude or ChatGPT project context – and treat it as my primary partner; the others are virtual subcontractors. This means that I can get a half-dozen or more reactions in minutes, which are then digested by the, let’s say, project manager, for assessment and a proposed action plan, typically in the form of a punch list. I recommend this approach as well.
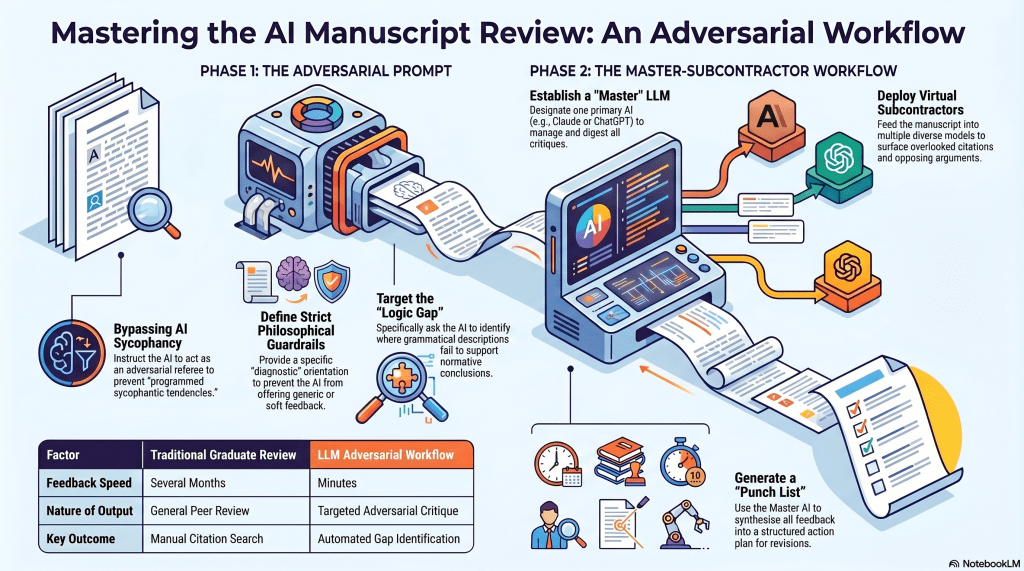
Closing shot
When I was in grad school, this part of the project would have taken months. As it is, I’ve been working on this project since COVID-19, but it’s been an on-and-off affair, accumulating research information and documentation all the while. The manuscript will be better off, and my position honed sharper over this expanse of time, so the delay was beneficial.
Would more time also be beneficial? Probably, but one needs to stop somewhere, and I’m likely facing diminishing marginal returns. If I go the way of Wittgenstein, I’ll reverse track and recant everything. And so it goes…
