This is not a philosophical post. Well, it’s about my personal philosophy of using LLMs and AI agents in my writing and publication workflow, which is a different thing. I’ll structure it as I might have done a music project back in the day, because that framing still makes more sense to me than anything the tech industry has come up with.
Preproduction
Not all projects make it into production. Others were never intended to. But they all begin with at least a kernel of an idea — and some arrive fully formed, as if sprung from the head of Zeus, already wearing armour and looking for a fight.
Pre-ideating
What the hell is pre-ideating? I just made it up for this use case because that’s how I roll.
As I understand it, some people need help thinking of topics. This is not my problem. My problem is managing ideas rather than generating them. I have a backlog that will outlast me, so I don’t use this step. But it exists, and it’s probably the most widely discussed AI use case in creative circles: you prompt the model to suggest themes, genres, or concepts. Give me five ideas for a mystery novel. Or, if you’re feeling ambitious: Give me five ideas for a research paper in quantum physics. The model obliges. Whether what comes back constitutes an idea in any philosophically interesting sense is a question I’ll save for another day.
Ideating
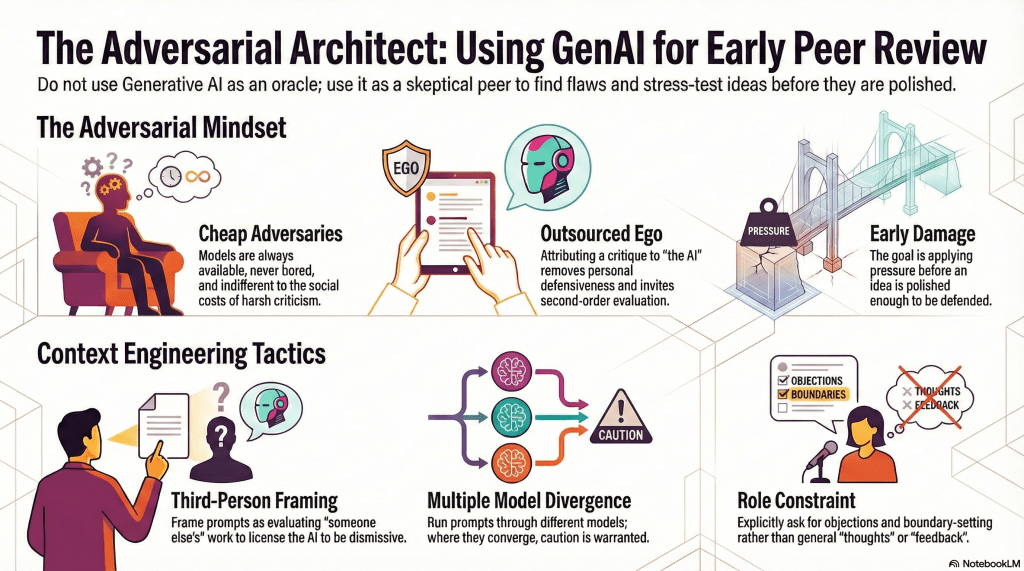
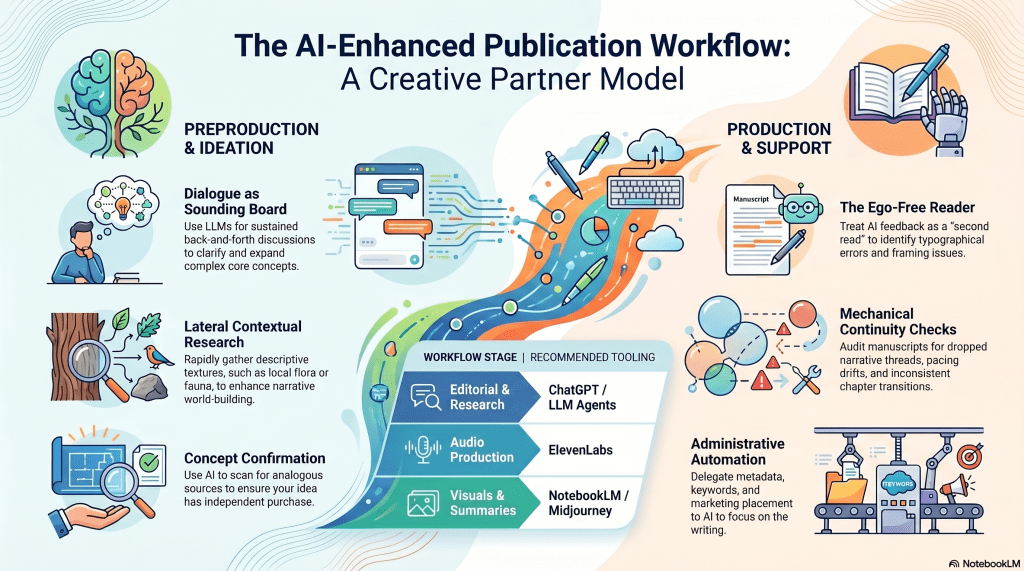
This is where I usually enter the process, and the ideation takes shape in one or several different ways. The most common is simply a discussion – a sustained back-and-forth. A recent example: I was reading Judith Butler’s Gender Trouble and found myself with clarifying questions at every turn. Not because Butler is unclear, but because the implications kept ramifying in directions I wanted to follow. That extended dialogue – with ChatGPT in this instance – eventually became the philosophical core of Two Kings, currently stalled in Production.
Butler’s argument about incest taboos as foundational to broader regimes of sex and gender regulation gave me a narrative frame. The conversation helped me see what I actually thought about it, which is the more important thing. The LLM didn’t give me the idea. It gave me a sounding board patient enough to entertain the idea at two in the morning – it was actually two in the afternoon, but who’s looking?
Research
Another obvious use case, and one I use regularly. Continuing the Butler example: I asked about several feminist theorists she references, wanting to understand the lineage I was stepping into. But here’s a cleaner illustration. Writing as Ridley Park, I produced a novella, Sustenance, set in Iowa. I’ve visited Iowa several times, but I needed local flora and fauna for descriptive texture in certain scenes, so I asked
In the old days, I’d have gone to Google, Wikipedia, or I’d track down an Encyclopædia Britannica. The process is faster now, and the results are generally better for this kind of lateral, contextual research. For anything where accuracy is genuinely load-bearing, I verify. That’s not a criticism of the tool; it’s just basic epistemic hygiene.
Confirmation
Sometimes I have an idea and want to know whether someone’s already done it because I have no interest in reinventing wheels, and even less in reinventing them badly.
So I ask: Has anyone written X? What are the most significant treatments of Y? What typically comes back is a list of a dozen or more analogous sources. I review them and decide: does my idea still have independent purchase, or am I just writing a worse version of something that already exists? Sometimes I sharpen the idea in response. Sometimes I incorporate what I find, either to build on it or to identify where the existing literature is misframed, assumes too much, or has quietly imported the wrong ontological grammar. This last move is something of a professional tic.
Production
Drafting
I don’t use LLMs for full drafts. This is an obvious use case for those who do, particularly if the goal is volume – especially for the person who has already prompted for which genre currently has high demand and low representation on Amazon, and is now logically committed to producing it. That’s a coherent workflow – just not mine.
Edits and Revision
This I use often, and it’s probably where I get the most consistent value. After writing a passage or section, I feed it to one or more models with context already established — thesis statement, abstract, outline, supporting documents. What comes back varies: typographical errors, odd phrasings, unintentional repetitions (and, occasionally, new ones the model has helpfully introduced), suggested rewrites, observations about framing. I don’t treat any of this as instruction. I treat it as a second read from a reader who has no ego investment in agreeing with me – and yet obviously does. The important distinction is input versus output. I’m not asking it to write. I’m asking it to respond to what I’ve written.
Continuity
Are there gaps? Dropped threads? Promises made in chapter two that chapter seven has forgotten entirely? This is a genuinely useful mechanical check – the kind of thing that’s easy to miss when you’ve been inside a manuscript long enough to stop reading what’s actually there.
Flow
Do the scenes and chapters move well? Does the transition from one section to another feel like a logical step or an unannounced lurch? Useful, with the caveat that models have aesthetic preferences that don’t always align with mine, and I treat their flow suggestions accordingly.
Pacing
Is the pacing appropriate — both for the genre and for the particular piece? These are separate questions. A thriller has genre conventions around pace; a particular thriller might have reasons to subvert them. The model can flag where the pacing drifts; the judgement call about whether that’s a problem remains mine.
Postproduction
Formatting and Layout
I use AI for ideas about how to present content on the page: chapter opens, font choices, sizes, running headers, folios. This is design at the level of convention and taste rather than technical execution. I find it useful as a first pass — it surfaces options I might not have considered, which I then either adopt, adapt, or discard.
Cover Ideas
Thematic cover concepts, whether or not I ultimately outsource the art and creative work. I find this a productive way to articulate what the book is doing before I have to explain it to someone else.
How To
I use InDesign, Illustrator, and Photoshop with competence but not expertise. For specific technical tasks – how do I do this thing in InDesign — I ask. I also still use Google, YouTube, and the occasional book. These are not competing resources; they’re complementary ones, and which I reach for depends on what kind of answer I need.
Support and Maintenance
Marketing and Placement
Target markets, genre positioning, how to frame the work for audiences who didn’t watch it being assembled. This is a legitimate use case and one I engage with, even if marketing remains a word I say with a slight internal wince.
I also use platforms like ElevenLabs for audio, NotebookLM for podcast summaries and infographics, and Nano Banana or Midjourney for images.
Keywords and Descriptions
Adjacent to marketing but more administrative in character, the metadata layer that determines whether the work is findable by the people who would want it. Less interesting to think about than almost anything else in the process, and therefore an excellent candidate for AI assistance.
None of the above replaces the work. That’s the point. The writing is still the writing.