
Legal Meaning and the Insufficiency of Language
The law has a charming habit of behaving as though language becomes precise the moment someone in a robe frowns at it. Words that drift cheerfully in ordinary life are summoned into court, sworn in, interrogated under oath, and expected to produce stable meaning under institutional pressure. When they fail, as they reliably do, the system does not conclude that language may be structurally insufficient for the task. It consults another authority. A dictionary. A drafting manual. A corpus database. A professor, if civilisation has really run out of excuses. Whatever. Any port in a storm. Then it calls the result interpretation, and everyone pretends the word was waiting there all along.
Watch the video below. It is an admirably clean illustration of exactly this.
What you just watched is not merely a curiosity about punctuation and gun laws. It is a diagnostic. And if you have read Chapter Five of A Language Insufficiency Hypothesis, you will recognise the pathology immediately.
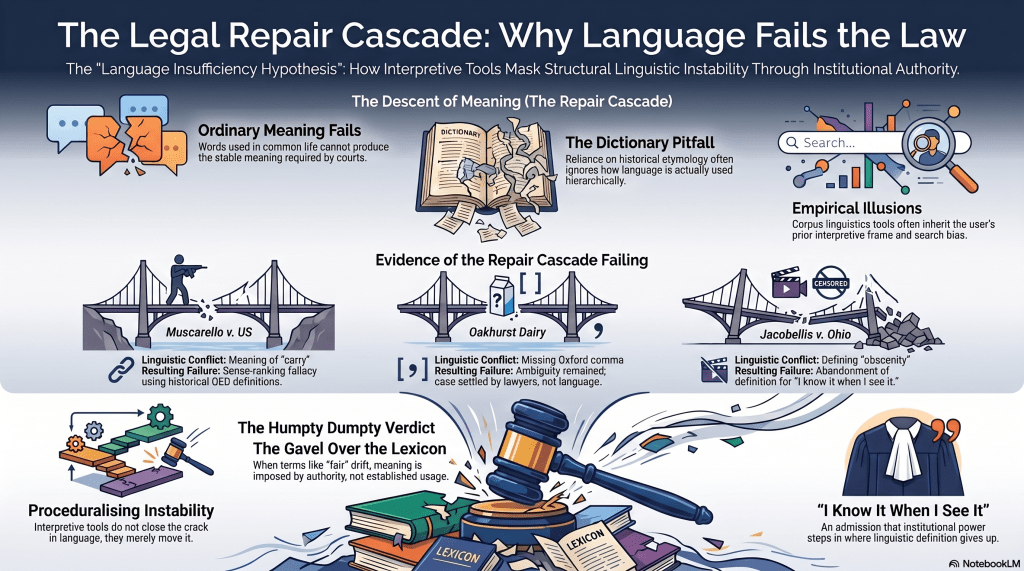
The Repair Cascade
The video gives you three cases, each one a new rung on the same ladder of failed repair.
tl;dr? They tend to make it up as they go to serve their power needs.
First, Muscarello v. United States (1998): A man transports a handgun in a locked glove compartment whilst conducting a drug transaction. The statute punishes anyone who ‘uses or carries a firearm’ during such a crime. The question is whether ‘carry’ includes a weapon stored in a vehicle. The Supreme Court reaches for the OED, finds that the earliest documented sense of carry includes conveyance by vehicle, and sends Muscarello to prison, where he eventually dies. Convenient etymology. Regrettable outcome.
The video notes – correctly, I might add (and so do) – that this is an instance of what linguists call the sense-ranking fallacy: assuming that the first definition listed is the primary one, rather than simply the earliest documented. The OED’s ordering is historical, not hierarchical. Why a US court chose the OED is a sign of refinement yet remarkably curious for an American institution.
Second, the Oakhurst Dairy case: Maine truck drivers sue for $10 million over a missing Oxford comma in a statutory overtime exemption. Both sides marshal gerunds, asyndeton, the Chicago Manual of Style, and the Maine legislative drafting manual, which explicitly prohibits the Oxford comma – making the ambiguity, in a sense, officially mandated. The case settles without a definitive ruling. The language did not yield a winner; the lawyers did. The hole wasn’t filled, but their pockets were.
Third, and most instructive, corpus linguistics arrives as the shiny new repair tool. Rather than trusting dictionaries, courts can now search large databases of actual language use to establish ‘ordinary meaning’. Progress. Empiricism. Science, even. And then, almost immediately, the next failure mode surfaces: the frequency fallacy (common usage is not the only permissible usage), corpus skew (many databases over-represent news articles), and search-framing (the ‘sanitation’ / ‘sanitise’ mask mandate case, where including a related but non-synonymous word shaped the results before analysis had even begun). The supposedly empirical tool inherited the user’s prior interpretive frame. Extraordinary.
Follow the sad path of the sad panda: ordinary meaning fails → dictionaries → dictionaries fail → corpus linguistics → corpus linguistics fails → methodological dispute about whether judges should be conducting quasi-scientific research from the bench at all.
And so it goes…
The LIH Reading
In A Language Insufficiency Hypothesis, Chapter Five argues that law is not a domain that occasionally encounters linguistic difficulty. It is a domain that is constitutively dependent on terms that live in the Contestables zone of the Effectiveness–Complexity Gradient – words like reasonable, fair, cruel, due process – terms indispensable to legal order and perpetually unstable within it. The Gradient’s prediction is blunt: the further a term drifts from stable, concrete reference, the more its meaning must be imposed by authority rather than established by usage.
The video illustrates this at the level of what might seem to be relatively simple terms – carry, distribution, sanitation – words that appear to sit closer to the Invariants end of the scale than to the Contestables. And yet even here, the institutional machinery creaks. If ‘carry’ cannot carry the weight of a single statute without Supreme Court intervention and a man’s death, what prospect does ‘reasonable’ have? Or ‘fair’? Or ‘obscene’?
Potter Stewart, as Chapter Five recounts, admitted in Jacobellis v. Ohio (1964) that he could not define obscenity in the abstract. ‘I know it when I see it‘, he declared. The remark is famous for its candour. It is less often noted that it is also an admission that language had simply given up, and that institutional authority stepped in to do what definition could not. The Court didn’t clarify what obscenity means, but it asserted the power to punish it anyway as it might later decide.
The video’s repair cascade is the same mechanism operating at a more mundane level. Legal interpretation doesn’t overcome linguistic insufficiency. It proceduralises it. Each interpretive tool displaces the instability onto a new surface. Dictionaries relocate the problem from statutory language to lexical authority. Corpus linguistics relocates it from lexical authority to sampling, frequency, and search design. The crack isn’t closed. It’s moved, with considerable administrative ceremony, and the ceremony is called clarity – clear as mud.
The law, in short, functions less as a dictionary than as a sovereign Humpty Dumpty: it decides what words mean when it matters, and enforces those meanings until it decides otherwise. The gavel is doing the work the lexicon cannot.
The Lesson That Isn’t
The lesson here isn’t that dictionaries are useless, corpus linguistics fraudulent, or judges uniquely obtuse. The lesson is structurally worse than that. Each repair works locally and fails architecturally. The law can stabilise meaning long enough to act, and acting is not nothing – Muscarello’s conviction required a determinate reading of ‘carry’, and the system produced one. But it can’t transmute contested language into invariant reference. It can only decide, punish, and maintain the fiction that the word was always waiting there, meaning exactly that.
Textualism – the interpretive philosophy that instructs judges to attend only to the words on the page, nothing more – is, viewed through an LIH lens, an institutionalised form of the Presumption of Effectiveness. It treats language as though it has a singular, determinate meaning recoverable by sufficiently rigorous attention, rather than as a system whose instability is structural rather than incidental. The words on the page are not a fixed source. They are the site of the problem.
If this framing resonates, Chapter Five of A Language Insufficiency Hypothesis develops the full argument – from the Gradient’s account of why legal language is structurally dependent on Contestables, through Potter Stewart’s famous abdication, to the Humpty Dumpty jurisprudence that inevitably follows. Available in paperback and hardcover from Philosophics Press.


