
Let’s begin with a confession: I loathe indexing.
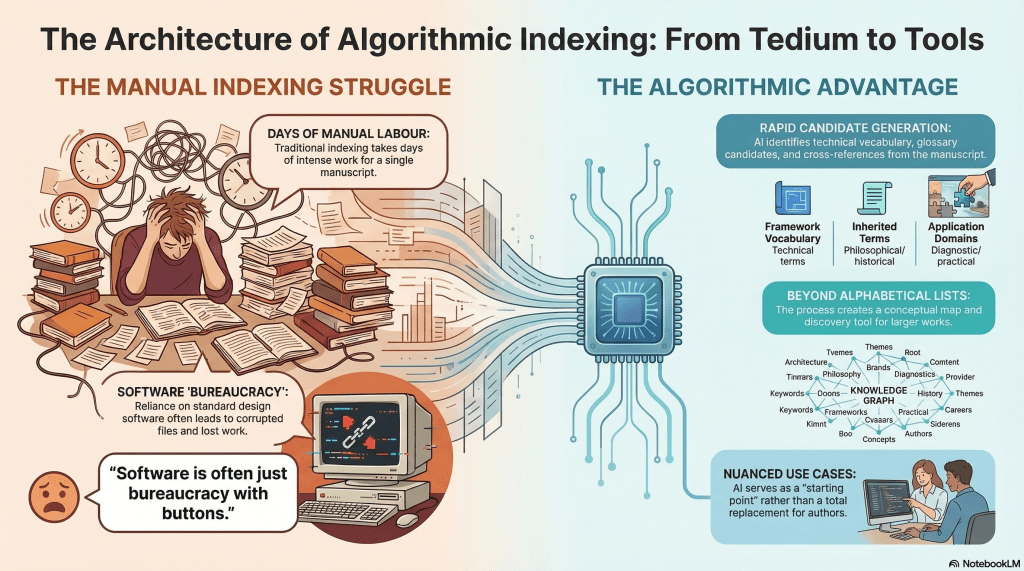
It takes me days to index one of my books. Longer when the technology decides to become sentient in the worst possible way, such as the time InDesign corrupted the index file and swallowed days of work whole. A charming little reminder that software is often just bureaucracy with buttons.
Today, while chatting with Claude (Opus 4.6), I mentioned that I should probably create an index for my current project. The manuscript is not fully reviewed and revised, but it is getting close. At this stage, I do not expect to add much of substance. I am more likely to subtract than expand.
Claude asked whether I wanted help generating a list of candidate terms from the manuscript.
Dois-je rédiger une liste de termes candidats à partir du manuscrit ?
I said yes, and it produced an embedded PDF: Index Term List – Architecture of Encounter. On first scan, it looks remarkably close to what I need. It is not merely a term list, either. It also proposes candidates for glossary entries, which is useful, even if I am not yet convinced I want to add a glossary. The book is already sitting at around 256 pages, and print production costs do not exactly reward philosophical generosity. The draft organises terms into five sections, including framework-specific technical vocabulary, inherited philosophical terms, proper names, traditions and programmes, and application domains and diagnostics. It also marks some entries as glossary candidates and notes likely cross-references.
One amusing detail is that some of the suggested references relate to epigraphs. I had not really considered indexing those. My inclination is still not to include them, but I admit the temptation is there.
The categorisation itself is also interesting. It makes a good deal of sense as a conceptual map or discovery tool, especially for a larger work. But it does not quite align with what most readers expect from an index, which is, bluntly, alphabetical and easy to raid.
Still, as a starting point, this is rather better than staring into the manuscript and pretending I enjoy this sort of thing.
Some people like to badmouth or trash-talk AI. I’m here to say that these people need to discover nuance and use cases.
’nuff said. What do you think? 🧐
