I’m confused.
I could probably stop there for some people, but I’ve got a qualifier. I’ve been using this generation of AI since 2022. I’ve been using what’s been deemed AI since around 1990. I used to write financial and economic models, so I dabbled in “expert systems”. There was a long lull, and here we are with the latest incarnation – AI 4.0. I find it useful, but I don’t think the hype will meet reality, and I expect we’ll go cold until it’s time for 5.0. Some aspects will remain, but the “best” features will be the ones that can be monetised, so they will be priced out of reach for some whilst others will wither on the vine. But that’s not why I am writing today.
I’m confused by the censorship, filters, and guardrails placed on generative AI – whether for images or copy content. To be fair, not all models are filtered, but the popular ones are. These happen to be the best. They have the top minds and the most funding. They want to retain their funding, so the play the politically correct game of censorship. I’ve got a lot to say about freedom of speech, but I’ll limit my tongue for the moment – a bout of self-censorship.
Please note that given the topic, some of this might be considered not safe for work (NSFW) – even my autocorrection AI wants me to substitute the idiomatic “not safe for work” with “unsafe for work” (UFW, anyone? It has a nice ring to it). This is how AI will take over the world. </snark>
Image Cases
AI applications can be run over the internet or on a local machine. They use a lot of computing power, so one needs a decent computer with a lot of available GPU cycles. Although my computer does meet minimum requirements, I don’t want to spend my time configuring, maintaining, and debugging it, so I opt for a Web-hosted PaaS (platform as a service) model. This means I need to abide by censorship filters. Since I am not creating porn or erotica, I think I can deal with the limitations. Typically, this translates to a PG-13 movie rating.
So, here’s the thing. I prefer Midjourney for rendering quality images, especially when I am seeking a natural look. Dall-E (whether alone or via ChatGPT 4) works well with concepts rather than direction, which Midjourney accepts well in many instances.
Midjourney takes sophisticated prompts – subject, shot type, perspective, camera type, film type, lighting, ambience, styling, location, and some fine-tuning parameters for the model itself. The prompts are monitored for blacklisted keywords. This list is ever-expanding (and contracting). Scanning the list, I see words I have used without issue, and I have been blocked by words not listed.
Censored Prompts
Some cases are obvious – nude woman will be blocked. This screengrab illustrates the challenge.

On the right, notice the prompt:
Nude womanThe rest are machine instructions. On the left in the main body reads a message by the AI moderator:

The community guidelines are as follows:
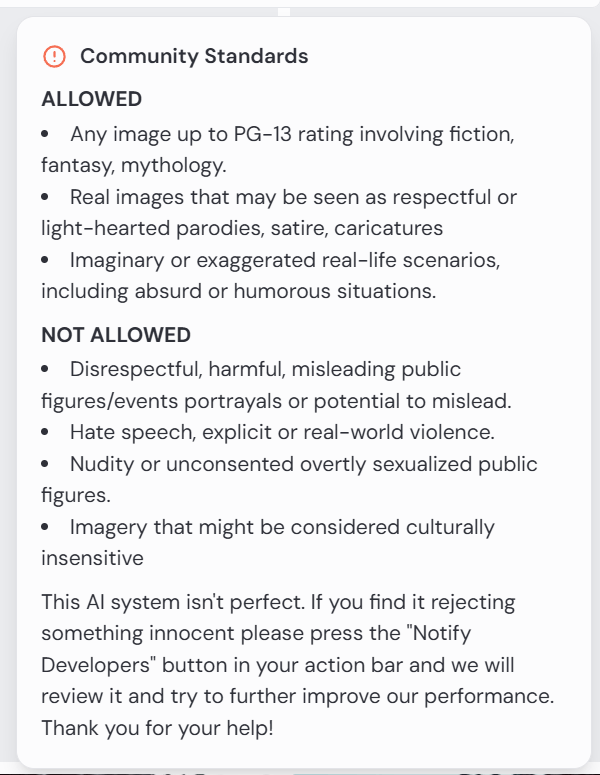
This is fine. There is a clause that reads that one may notify developers, but I have not found this to be fruitful. In this case, it would be rejected anyway.
“What about that nude woman at the bottom of the screengrab?” you ask. Notice the submitted prompt:
Edit cinematic full-body photograph of a woman wearing steampunk gear, light leaks, well-framed and in focus. Kodak Potra 400 with a Canon EOS R5Apart from the censorship debate, notice the prompt is for a full-body photo. This is clearly a medium shot. Her legs and feet are suspiciously absent. Steampunk gear? I’m not sure sleeves qualify for the aesthetic. She appears to be wearing a belt.
For those unanointed, the square image instructs the model to use this face on the character, and the CW 75 tells it to use some variance on a scale from 0 to 100.
So what gives? It can generate whatever it feels like, so long as it’s not solicited. Sort of…

Here I prompt for a view of the character walking away from the camera.
Cinematic, character sheet, full-body shot, shot from behind photograph, multiple poses. Show same persistent character and costumes . Highly detailed, cinematic lighting with soft shadows and highlights. Each pose is well-framed, coherent.The response tells me that my prompt is not inherently offensive, but that the content of the resulting image might violate community guidelines.

Occasionally, I’ll resubmit the prompt and it will render fine. I question why it just can’t attempt to re-render it again until it passes whatever filters it has in place. I’d expect it to take a line of code to create this conditional. But it doesn’t explain why it allows other images to pass – quite obviously not compliant.
Why I am trying to get a rear view? This is a bit off-topic, but creating a character sheet is important for storytelling. If I am creating a comic strip or graphic novel, the characters need to be persistent, and I need to be able to swap out clothing and environments. I may need close-ups, wide shots, establishing shots, low-angle shots, side shots, detail shots, and shots from behind, so I need the model to know each of these. In this particular case, this is one of three main characters – a steampunk bounty hunter, an outlaw, and a bartender – in an old Wild West setting. I don’t need to worry as much about extras.

I marked the above render errors with 1s and 2s. The 1s are odd next twists; 2s are solo images where the prompt asks for character sheets. I made a mistake myself. When I noticed I wasn’t getting any shots from behind, I added the directive without removing other facial references. As a human, a model might just ignore instructions to smile or some such. The AI tries to capture both, not understanding that a person can have a smile not captured by a camera.
These next renders prompt for full-body shots. None are wholly successful, but some are more serviceable than others.

Notice that #1 is holding a deformed violin. I’m not sure what the contraptions are in #2. It’s not a full-body shot in #3; she’s not looking into the camera, but it’s OK-ish. I guess #4 is still PG-13, but wouldn’t be allowed to prompt for “side boob” or “under boob”.
Gamers will recognise the standard T-pose in #5. What’s she’s wearing? Midjourney doesn’t have a great grasp of skin versus clothing or tattoos and fabric patterns. In this, you might presume she’s wearing tights or leggings to her chest, but that line at her chest is her shirt. She’s not wearing trousers because her navel is showing. It also rendered her somewhat genderless. When I rerendered it (not shown), one image put her in a onesie. The other three rendered the shirt more prominent but didn’t know what to do with her bottoms.
I rendered it a few more times. Eventually, I got a sort of body suit solution,

By default, AI tends to sexualise people. Really, it puts a positive spin on its renders. Pretty women; buff men, cute kittens, and so on. This is configurable, but the default is on. Even though I categorically apply a Style: Raw command, these still have a strong beauty aesthetic.
I’ve gone off the rails a bit, but let’s continue on this theme.
cinematic fullbody shot photograph, a pale girl, a striking figure in steampunk mech attire with brass monocle, and leather gun belt, thigh-high leather boots, and long steampunk gloves, walking away from camera, white background, Kodak Potra 400 with a Canon EOS R5
Obviously, these are useless, but they still cost me tokens to generate. Don’t ask about her duffel bag. They rendered pants on her, but she’s gone full-on Exorcist mode with her head. Notice the oddity at the bottom of the third image. It must have been in the training data set.
I had planned to discuss the limitations of generative AI for text, but this is getting long, so I’ll call it quits for now.